
Building a Job Listings Scraper: Aggregating Employment Data
By khoanc, at: March 1, 2023, 3:32 p.m.
Estimated Reading Time: __READING_TIME__ minutes


In today's job market, aggregating employment data from multiple sources can provide valuable insights and opportunities for job seekers. A job listings scraper can automate the collection of job postings from various websites, helping you create a centralized database of employment opportunities.
In this post, we'll guide you through building a job listings scraper using Python, focusing on two example job boards: Status Health Partners and Mayo Clinic.
Why Build a Job Listings Scraper?
A job listings scraper can be beneficial for several reasons:
- Job Seekers: Get access to a wider range of job opportunities.
- Recruiters: Identify trends and popular job titles.
- Data Analysts: Analyze job market trends and demands.
- Aggregators: Create a comprehensive job board from multiple sources.
Tools and Libraries
For this project, we'll use the following tools and libraries:
- Python: The programming language we'll use.
- BeautifulSoup: For parsing HTML content.
- Requests: For making HTTP requests to web pages.
- Pandas: For storing and manipulating the scraped data.
You can install these libraries using pip:
pip install beautifulsoup4 requests pandas
Step-by-Step Guide
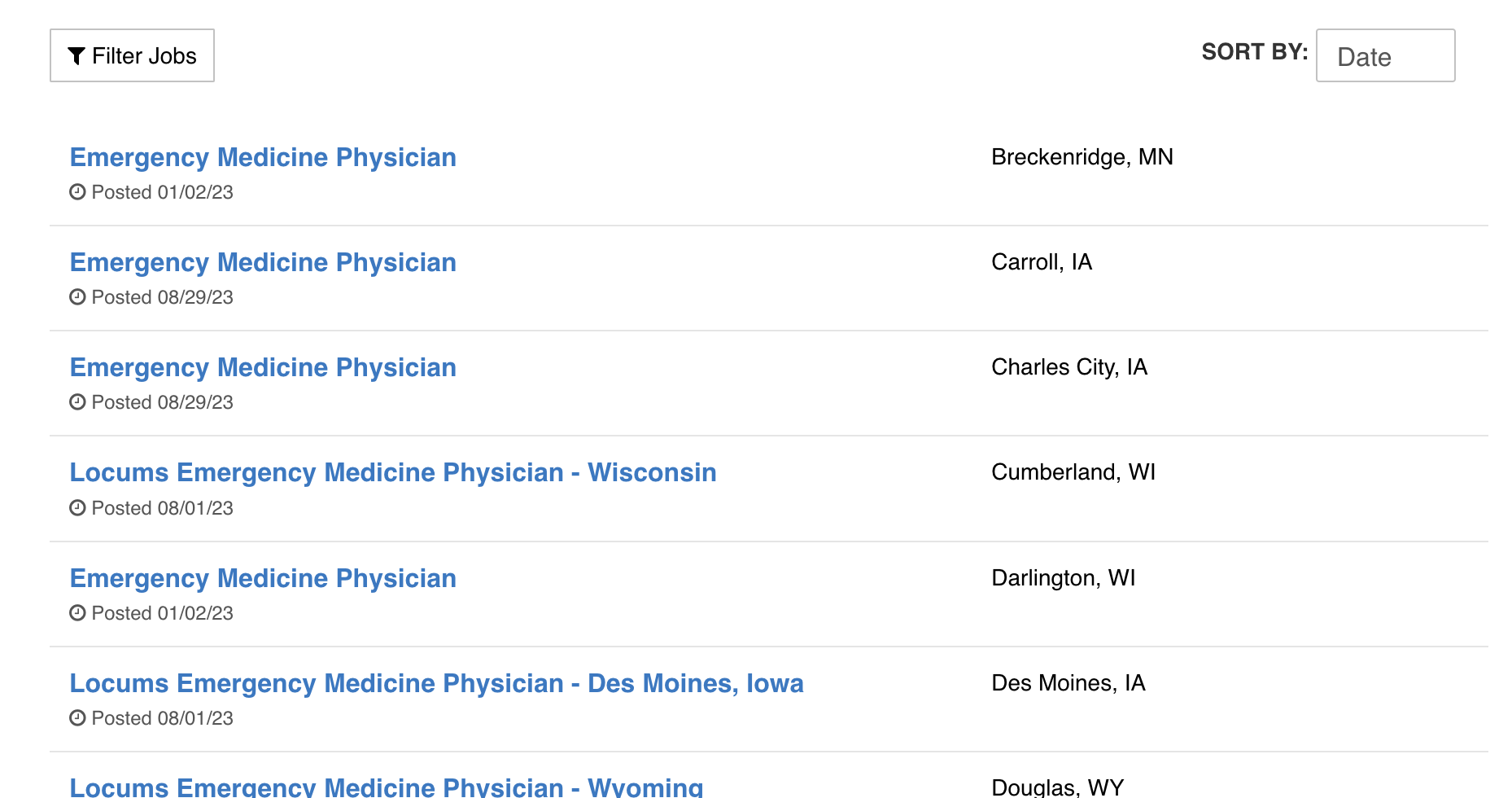
1. Inspect the Web Pages
First, we need to inspect the job listing pages to understand their structure. We look for patterns in the HTML that we can use to extract job details.
2. Sending HTTP Requests
We use the requests library to fetch the HTML content of the job listing pages.
import requests
from bs4 import BeautifulSoup
def get_page_content(url):
response = requests.get(url)
if response.status_code == 200:
return response.content
else:
return None
url = 'https://jobs.statushp.com/'
page_content = get_page_content(url)
3. Parsing HTML Content
Next, we use BeautifulSoup to parse the HTML content and extract job details such as job title, company, location, and link to the job posting.
def parse_statushp_jobs(page_content):
soup = BeautifulSoup(page_content, 'html.parser')
job_listings = []
for job_card in soup.find_all('div', class_='job-card'):
job_title = job_card.find('h2', class_='job-title').text.strip()
company = 'Status Health Partners'
location = job_card.find('div', class_='location').text.strip()
job_link = job_card.find('a', class_='apply-button')['href']
job_listings.append({
'Job Title': job_title,
'Company': company,
'Location': location,
'Job Link': job_link
})
return job_listings
jobs_statushp = parse_statushp_jobs(page_content)
4. Scraping from Multiple Sources
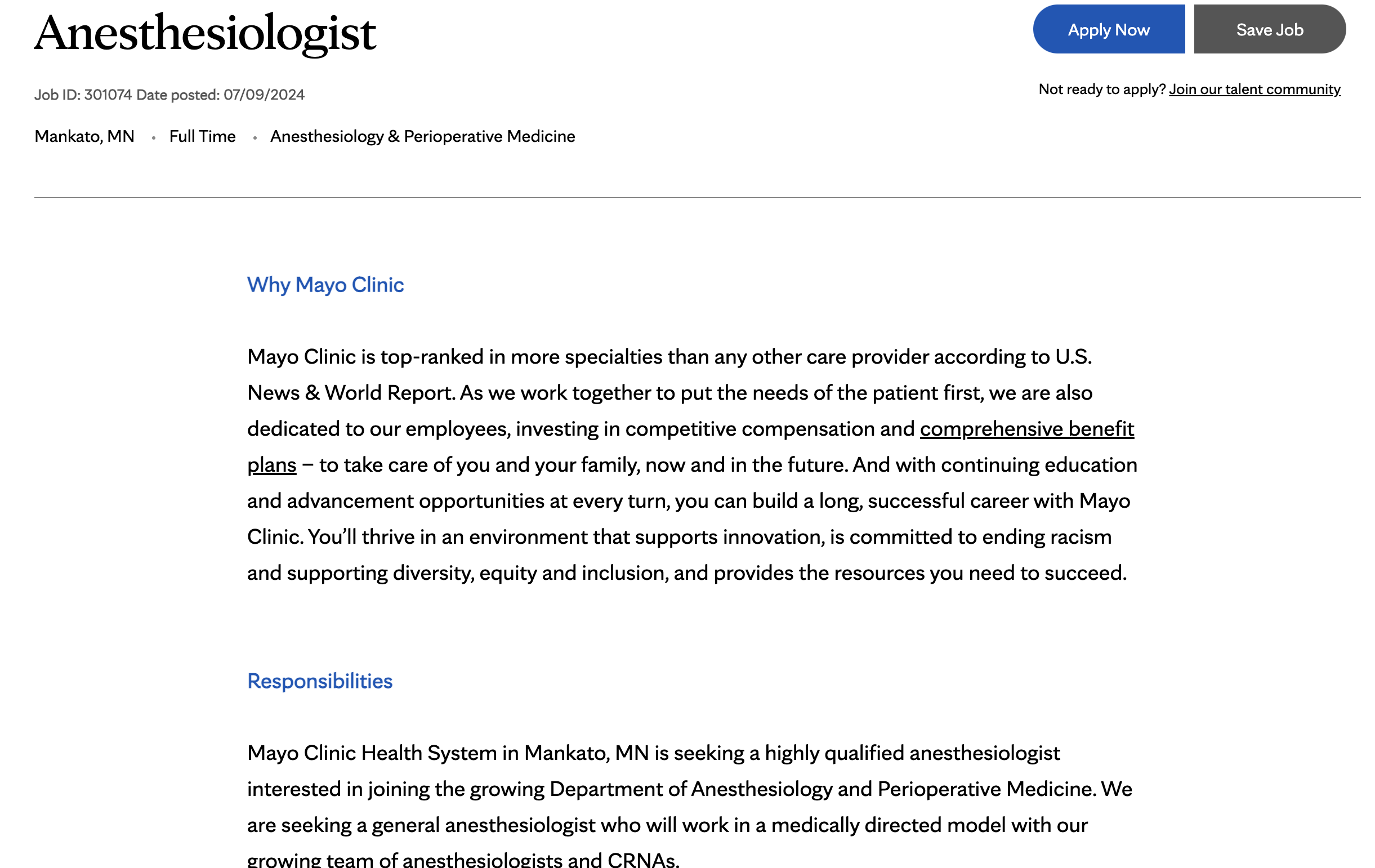
We can follow a similar process to scrape job listings from Mayo Clinic's job board.
url_mayo = 'https://jobs.mayoclinic.org/'
page_content_mayo = get_page_content(url_mayo)
def parse_mayoclinic_jobs(page_content):
soup = BeautifulSoup(page_content, 'html.parser')
job_listings = []
for job_card in soup.find_all('div', class_='job-card'):
job_title = job_card.find('h2', class_='job-title').text.strip()
company = 'Mayo Clinic'
location = job_card.find('div', class_='location').text.strip()
job_link = job_card.find('a', class_='apply-button')['href']
job_listings.append({
'Job Title': job_title,
'Company': company,
'Location': location,
'Job Link': job_link
})
return job_listings
jobs_mayo = parse_mayoclinic_jobs(page_content_mayo)
5. Aggregating the Data
We combine the scraped data from both sources into a single Pandas DataFrame.
import pandas as pd
all_jobs = jobs_statushp + jobs_mayo
df_jobs = pd.DataFrame(all_jobs)
print(df_jobs)
6. Saving the Data
Finally, we can save the aggregated job listings to a CSV file for further analysis or use.
df_jobs.to_csv('aggregated_job_listings.csv', index=False)
Conclusion
Building a job listings scraper can provide valuable insights and opportunities for job seekers, recruiters, and data analysts. By using Python and libraries like BeautifulSoup and Pandas, you can automate the process of collecting job postings from multiple sources and create a comprehensive database of employment opportunities. This guide provides a starting point for building your own job listings scraper, which you can extend and customize to suit your specific needs.




