
Using Puppeteer for Dynamic Web Scraping
By JoeVu, at: April 30, 2024, 11:19 p.m.
Estimated Reading Time: __READING_TIME__ minutes


Today, while static web scraping can be straightforward, many modern websites load content dynamically using JavaScript. Traditional scraping tools may not be able to capture this content effectively. Puppeteer, a Node.js library that provides a high-level API to control headless Chrome or Chromium, is designed to handle such cases. This guide will explore how to use Puppeteer for dynamic web scraping.
Introduction to Puppeteer
Puppeteer allows you to automate and control web browsers programmatically. It can navigate to web pages, execute JavaScript, take screenshots, and extract data. Here's how to get started with Puppeteer for dynamic web scraping:
Installing Puppeteer
First, you need to install Puppeteer. You can do this using npm (Node Package Manager):
npm install puppeteer
Basic Puppeteer Script
Here is a basic Puppeteer script that navigates to a webpage and extracts some content:
const puppeteer = require('puppeteer');
(async () => {
// Launch a headless browser
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Navigate to the webpage
await page.goto('https://example.com');
// Extract content
const data = await page.evaluate(() => {
return document.querySelector('h1').innerText;
});
console.log(data); // Output: Example Domain
// Close the browser
await browser.close();
})();
Handling Dynamic Content
To scrape dynamic content, you may need to wait for certain elements to load. Puppeteer provides several methods to handle this:
Waiting for Elements to Load
You can use page.waitForSelector to wait for an element to appear in the DOM before proceeding:
await page.goto('https://example.com');
await page.waitForSelector('h1'); // Wait for the h1 element to load
const data = await page.evaluate(() => {
return document.querySelector('h1').innerText;
});
console.log(data)
Interacting with the Page
Puppeteer allows you to interact with the page, such as clicking buttons or filling out forms. This is useful for scraping content that requires user interaction:
await page.goto('https://example.com');
await page.click('#button'); // Click a button
await page.waitForSelector('#result'); // Wait for the result to load
const result = await page.evaluate(() => {
return document.querySelector('#result').innerText;
});
console.log(result);
Handling Pagination
Many websites use pagination to display large amounts of data. Puppeteer can handle pagination by navigating through pages programmatically:
Ex: BrainyQuote
const results = [];
await page.goto('https://www.brainyquote.com/topics/motivational-quotes');
while (true) {
const data = await page.evaluate(() => {
return Array.from(document.querySelectorAll('a[title="view quote"]')).map(item => item.innerText);
});
results.push(...data);
const nextButton = await page.$('.next');
if (!nextButton) break;
await Promise.all([
page.waitForNavigation(),
nextButton.click(),
]);
}
console.log(results);
Taking Screenshots
Puppeteer can also capture screenshots of web pages, which can be useful for documentation or debugging:
await page.goto('https://www.brainyquote.com/quotes/philip_sidney_160088');
await page.screenshot({ path: 'philip-sidney-160088.png' });
Advanced Features
Puppeteer offers many advanced features for complex scraping tasks:
Emulating Devices
You can emulate different devices to test responsive designs or scrape mobile versions of websites:
const iPhone = puppeteer.devices['iPhone 6'];
await page.emulate(iPhone);
await page.goto('https://www.brainyquote.com/quotes/philip_sidney_160088');
Executing Custom JavaScript
Puppeteer allows you to execute custom JavaScript in the context of the page, giving you full control over the web page's behavior:
await page.evaluate(() => {
// Custom JavaScript
document.querySelector('h1').style.color = 'red';
})
Handling Authentication
If a website requires login (ex: https://www.linkedin.com/login), Puppeteer can automate the login process:
await page.goto('https://www.linkedin.com/login');
await page.type('#username', 'yourUsername');
await page.type('#password', 'yourPassword');
await page.click('button[type=submit]');
await page.waitForNavigation()
A real example with code
Requirements: Collect quotes from https://www.brainyquote.com/topics/motivational-quotes using Puppeteer
Answer:
const puppeteer = require('puppeteer');
(async () => {
// Launch the browser
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
// Go to the website
await page.goto('https://www.brainyquote.com/topics/motivational-quotes', { waitUntil: 'networkidle2' });
// Wait for the quotes to load
await page.waitForSelector('.bqQt');
// Scrape the quotes
const quotes = await page.evaluate(() => {
const quoteElements = document.querySelectorAll('a[title="view quote"]');
const quotesArray = [];
quoteElements.forEach(quoteElement => {
const text = quoteElement.innerText;
quotesArray.push(text);
});
return quotesArray;
});
// Log the quotes
console.log(quotes);
// Close the browser
await browser.close();
})();
Pros and Cons of Puppeteer
Pros
-
Headless Browser Automation: Puppeteer can run in a headless mode, meaning it can automate browsing tasks without opening a graphical user interface, which is useful for automated testing and scraping.
-
Full Browser Control: It offers comprehensive control over the Chrome browser, allowing you to perform actions such as navigating to web pages, clicking buttons, filling forms, and capturing screenshots.
-
JavaScript Execution: Puppeteer can execute JavaScript within the context of the web page, enabling it to interact with dynamic content and single-page applications (SPAs).
-
Handling Complex Scenarios: Puppeteer can handle complex scraping scenarios like handling authentication, navigating through multiple pages, and interacting with elements on the page.
-
Device Emulation: It can emulate different devices and screen resolutions, which is helpful for testing responsive web designs and scraping mobile versions of websites.
-
Automated Testing: Puppeteer is commonly used for automated testing of web applications, allowing developers to write and run tests that simulate user interactions.
-
Screen Capture and PDF Generation: It can capture screenshots and generate PDFs of web pages, useful for creating visual documentation or reports.
Cons
-
Resource-Intensive: Running a full browser, even in headless mode, can be resource-intensive compared to lighter scraping libraries like BeautifulSoup or Cheerio.
-
Setup and Configuration: Setting up Puppeteer and managing the browser binaries can be more complex than using simpler scraping tools.
-
JavaScript Dependency: Since Puppeteer is a Node.js library, you need to be familiar with JavaScript and Node.js to use it effectively.
-
Performance Overhead: The overhead of launching and managing browser instances can impact performance, especially when scraping large amounts of data.
-
Blocked by Some Websites: Some websites have measures to detect and block headless browsers, making it harder to scrape content without getting blocked.
-
Maintenance: Keeping Puppeteer up-to-date and compatible with the latest versions of Chrome/Chromium can require regular maintenance.
-
Not Always Necessary: For static pages or simple scraping tasks, using Puppeteer can be overkill. Lighter libraries might be more efficient for such tasks.
Compare Puppeteer/JS and PlayWright/Python
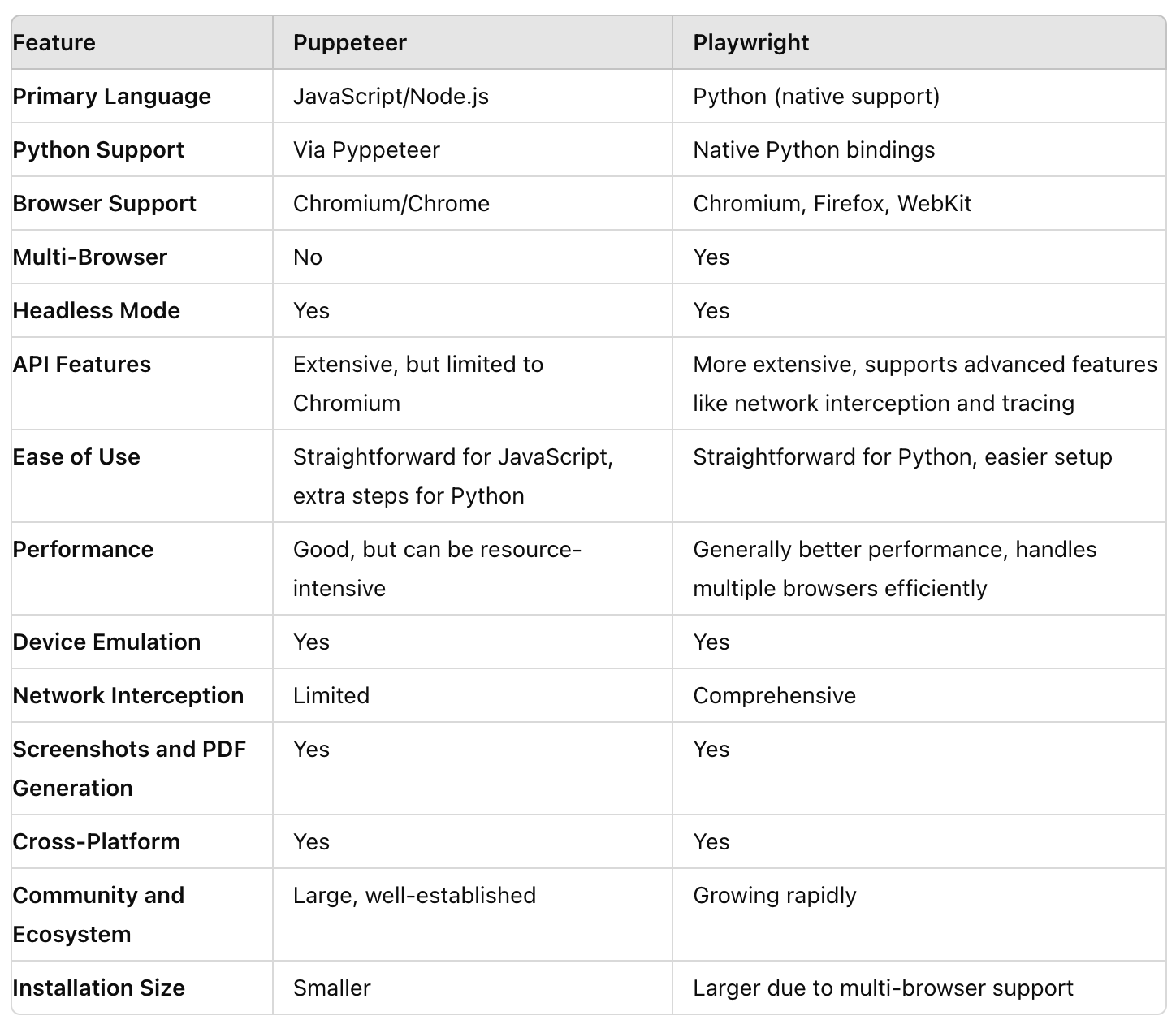
Conclusion
Puppeteer is a powerful tool for dynamic web scraping, capable of handling complex interactions and dynamic content that traditional scraping tools cannot manage. By mastering Puppeteer, you can scrape data from modern web applications more effectively and efficiently.




