
求人情報スクレイパーの構築:雇用データの集約
By khoanc, at: 2023年3月1日15:32
予想読書時間: __READING_TIME__ 分


今日の求人市場では、複数のソースからの求人データの集約は、求職者にとって貴重な洞察と機会を提供できます。求人情報スクレイパーは、さまざまなウェブサイトから求人情報を自動的に収集し、雇用機会の中央データベースを作成するのに役立ちます。
この記事では、Pythonを使用して求人情報スクレイパーを構築する方法を説明し、Status Health Partners と Mayo Clinic.の2つの求人サイトを例に説明します。
求人情報スクレイパーを作成する理由
求人情報スクレイパーは、いくつかの理由で役立ちます。
- 求職者:より幅広い求人情報にアクセスできます。
- 採用担当者:トレンドや人気のある職種を特定できます。
- データアナリスト:求人市場のトレンドと需要を分析できます。
- アグリゲーター:複数のソースから包括的な求人サイトを作成できます。
ツールとライブラリ
このプロジェクトでは、次のツールとライブラリを使用します。
- Python:使用するプログラミング言語です。
- BeautifulSoup:HTMLコンテンツの解析に使用します。
- Requests:ウェブページへのHTTPリクエストを行うために使用します。
- Pandas:スクレイピングされたデータの保存と操作に使用します。
これらのライブラリはpipを使用してインストールできます。
pip install beautifulsoup4 requests pandas
ステップバイステップガイド
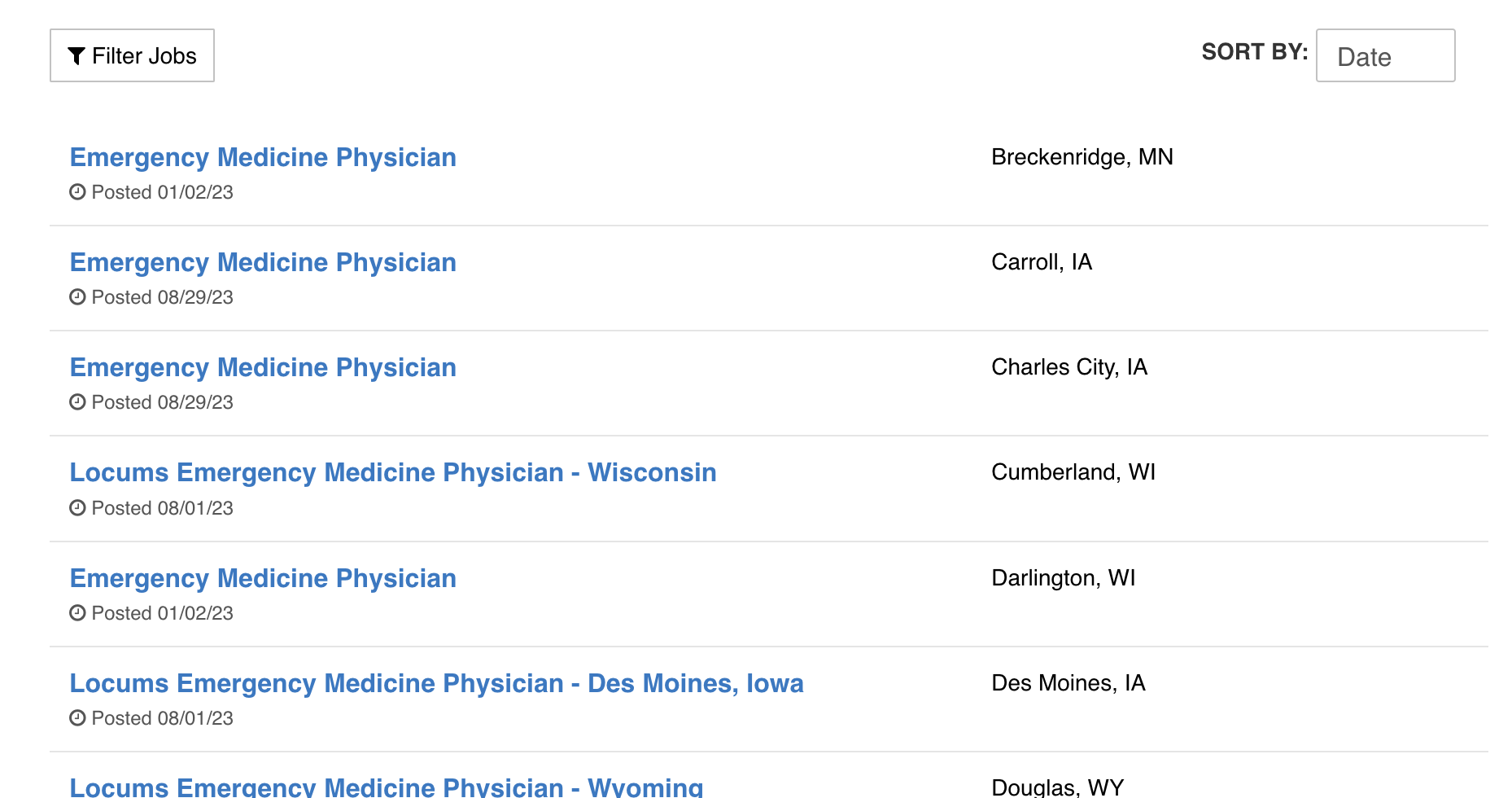
1. ウェブページの検証
まず、求人情報のページを検証して、その構造を理解する必要があります。求人情報の詳細を抽出するために使用できるHTMLのパターンを探します。
2. HTTP Requestsの送信
requestsライブラリを使用して、求人情報のページのHTMLコンテンツを取得します。
import requests
from bs4 import BeautifulSoup
def get_page_content(url):
response = requests.get(url)
if response.status_code == 200:
return response.content
else:
return None
url = 'https://jobs.statushp.com/'
page_content = get_page_content(url)
3. HTMLコンテンツの解析
次に、BeautifulSoupを使用してHTMLコンテンツを解析し、職名、会社、場所、求人情報のリンクなどの求人情報の詳細を抽出します。
def parse_statushp_jobs(page_content):
soup = BeautifulSoup(page_content, 'html.parser')
job_listings = []
for job_card in soup.find_all('div', class_='job-card'):
job_title = job_card.find('h2', class_='job-title').text.strip()
company = 'Status Health Partners'
location = job_card.find('div', class_='location').text.strip()
job_link = job_card.find('a', class_='apply-button')['href']
job_listings.append({
'Job Title': job_title,
'Company': company,
'Location': location,
'Job Link': job_link
})
return job_listings
jobs_statushp = parse_statushp_jobs(page_content)
4. 複数のソースからのスクレイピング
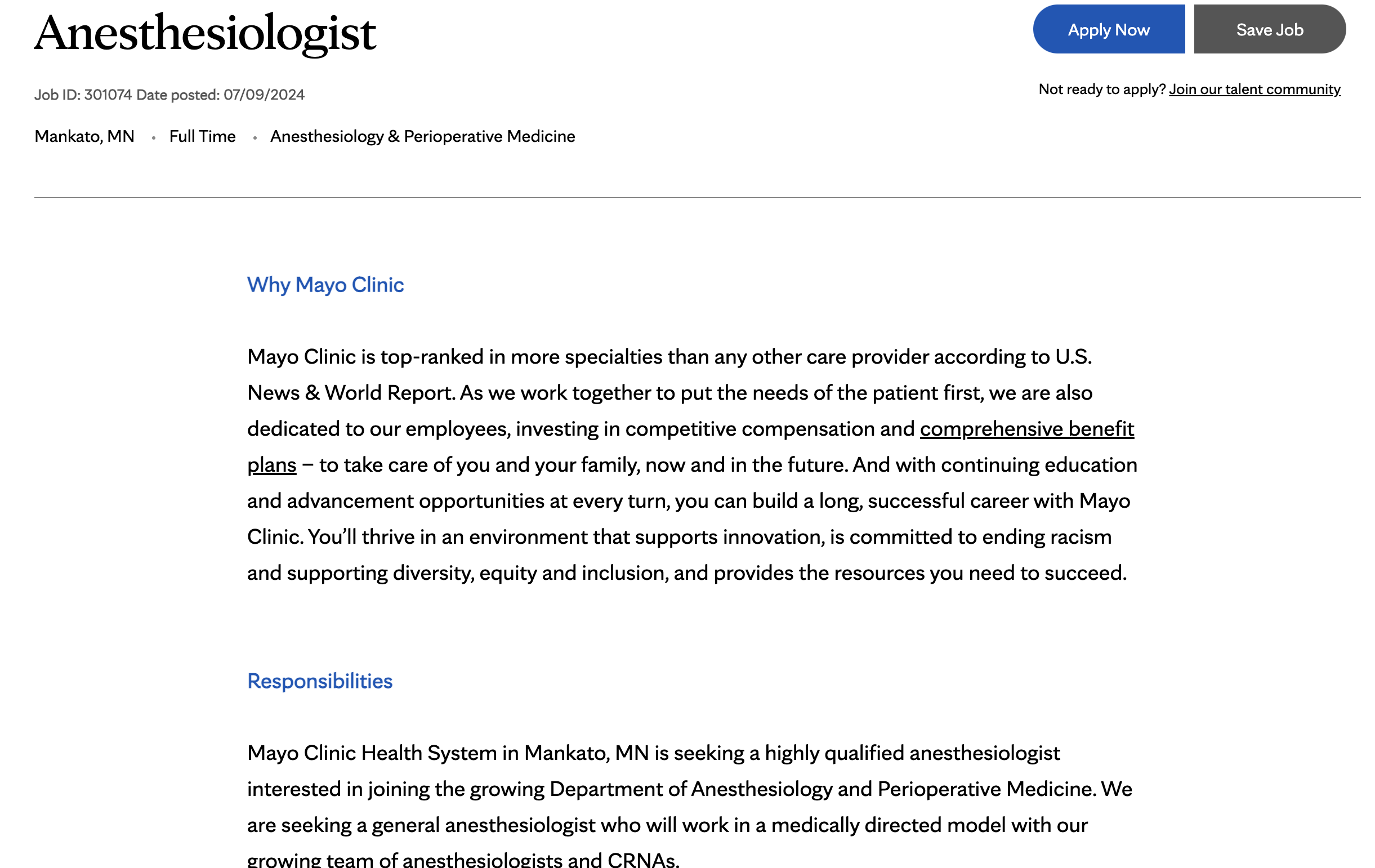
Mayo Clinicの求人情報サイトからも同様の方法で求人情報をスクレイピングできます。
url_mayo = 'https://jobs.mayoclinic.org/'
page_content_mayo = get_page_content(url_mayo)
def parse_mayoclinic_jobs(page_content):
soup = BeautifulSoup(page_content, 'html.parser')
job_listings = []
for job_card in soup.find_all('div', class_='job-card'):
job_title = job_card.find('h2', class_='job-title').text.strip()
company = 'Mayo Clinic'
location = job_card.find('div', class_='location').text.strip()
job_link = job_card.find('a', class_='apply-button')['href']
job_listings.append({
'Job Title': job_title,
'Company': company,
'Location': location,
'Job Link': job_link
})
return job_listings
jobs_mayo = parse_mayoclinic_jobs(page_content_mayo)
5. データの集約
両方のソースからスクレイピングされたデータを1つのPandas DataFrameにまとめます。
import pandas as pd
all_jobs = jobs_statushp + jobs_mayo
df_jobs = pd.DataFrame(all_jobs)
print(df_jobs)
6. データの保存
最後に、集約された求人情報をCSVファイルに保存して、さらに分析したり使用したりできます。
df_jobs.to_csv('aggregated_job_listings.csv', index=False)
結論
求人情報スクレイパーを作成することで、求職者、採用担当者、データアナリストにとって貴重な洞察と機会が得られます。PythonとBeautifulSoup、Pandasなどのライブラリを使用することで、複数のソースから求人情報を収集し、包括的な雇用機会データベースを作成するプロセスを自動化できます。このガイドは、独自の求人情報スクレイパーを作成するための出発点であり、特定のニーズに合わせて拡張およびカスタマイズできます。




