
リレーショナルデータベース:基礎から将来のトレンドとイノベーションまで
By JoeVu, at: 2023年9月6日17:06
予想読書時間: __READING_TIME__ 分


1. はじめに
データがかつてない速度で生成され消費されるデジタル時代において、この貴重な資源を管理するデータベースの役割は過大評価することはできません。さまざまなデータベースモデルの中でも、リレーショナルデータベースは、現代のデータ管理システムの基盤として際立っています。 これらは、データを構造化して効率的に整理、保存、および取得する手段を提供します。この記事では、リレーショナルデータベースの基礎を探求し、データモデリング、構造化照会言語(SQL)、正規化技法など、重要な概念を詳しく調べます。
データベースの簡単な歴史
リレーショナルデータベースの重要性を理解するには、その歴史的発展を振り返ってみると役立ちます。何らかの形でデータベースは、コンピューティングの初期から存在していました。しかし、リレーショナルデータベースモデルの誕生は、コンピューター科学者エドガー・F・コッドが画期的な概念を発表した1970年代にまで遡ることができます。
コッドのアイデアはシンプルでありながら革命的でした。データを行と列で構成される表に整理し、これらの表間の関係を確立するというものです。この革新は、データの保存と取得に対するより直感的で構造化されたアプローチへの道を開きました。リレーショナルデータベースモデルのエレガンスと効率性はすぐに普及し、今日の多くのデータ駆動型アプリケーションとシステムの基盤となっています。
主な利点
-
構造化データストレージ:データを構造化された表に整理し、データの整合性と一貫性を確保します。
-
データ整合性:主キーや外部キーなどのデータ整合性制約を適用して、データの正確性と信頼性を維持します。
-
柔軟なクエリ:リレーショナルデータベースのクエリ言語であるSQLは、データを取得および操作するための強力で柔軟な方法を提供します。
-
スケーラビリティ:多くのリレーショナルデータベース管理システム(RDBMS)は、スケーラビリティオプションを提供しており、企業は増え続けるデータセットを効率的に処理できます。
-
ACID特性:ACID(原子性、一貫性、独立性、耐久性)特性に従い、トランザクションの信頼性を確保します。
欠点
-
固定スキーマ:事前に定義されたスキーマが必要なため、急速に変化するデータ構造に適応することが困難です。
-
パフォーマンスのスケーリング:リレーショナルデータベースを水平方向にスケーリングすることは複雑でコストがかかる可能性があり、大量のデータとトラフィックを処理する能力が制限されます。
-
複雑さ:特に大規模で複雑なデータセットの場合、リレーショナルデータベースの設計と保守は複雑になる可能性があります。
-
正規化のオーバーヘッド:正規化は冗長性を削減しますが、複数の表結合によるクエリのパフォーマンスに複雑さを招く可能性があります。
-
ベンダーロックイン:特定のRDBMSを選択すると、ベンダーロックインにつながる可能性があり、他のシステムに移行することが困難になります。
2. リレーショナルデータベースとは何か?
リレーショナルデータベースは、現代のデータ管理システムの基礎となるコンポーネントであり、データの整理に対する構造化された効率的なアプローチで知られています。このセクションでは、リレーショナルデータベースの中核となる原則、主要なコンポーネント、およびデータ管理の世界における重要性を探ります。
定義と主要なコンポーネント
基本的に、リレーショナルデータベースは表に整理されたデータの集合です。これらの表は行と列で構成されており、各行は一意のレコードまたはエントリを表し、各列はそのレコードの特定の属性またはフィールドを表します。
主要なコンポーネント:
- 表:リレーショナルデータベースにおける組織の基本単位です。
- 行:各行は、単一のレコード、エンティティ、またはデータポイントを表します。
- 列:列は、表に保存されているデータの属性またはプロパティを定義します。
- キー:主キーや外部キーなどのキーは、表間の関係を確立します。
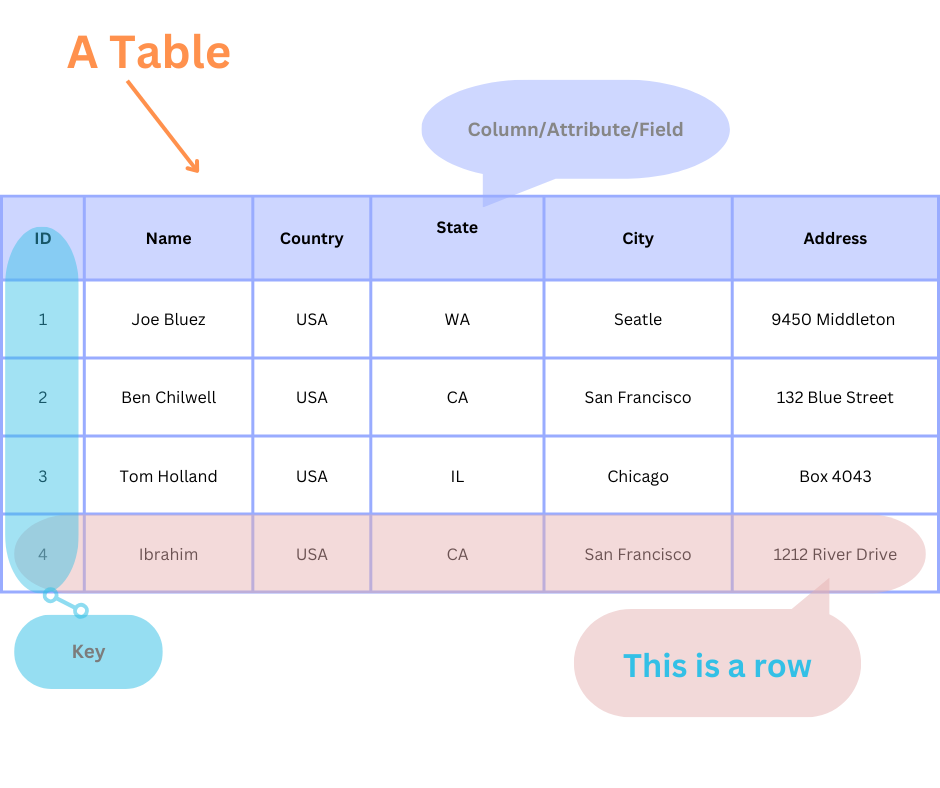
リレーショナルデータベースの例
簡単な例で説明しましょう。オンライン書店のためのデータを管理しているとします。「ISBN」、「タイトル」、「著者」、「価格」などの列を持つ「書籍」表があるかもしれません。この表の各行は、一意の書籍エントリを表します。
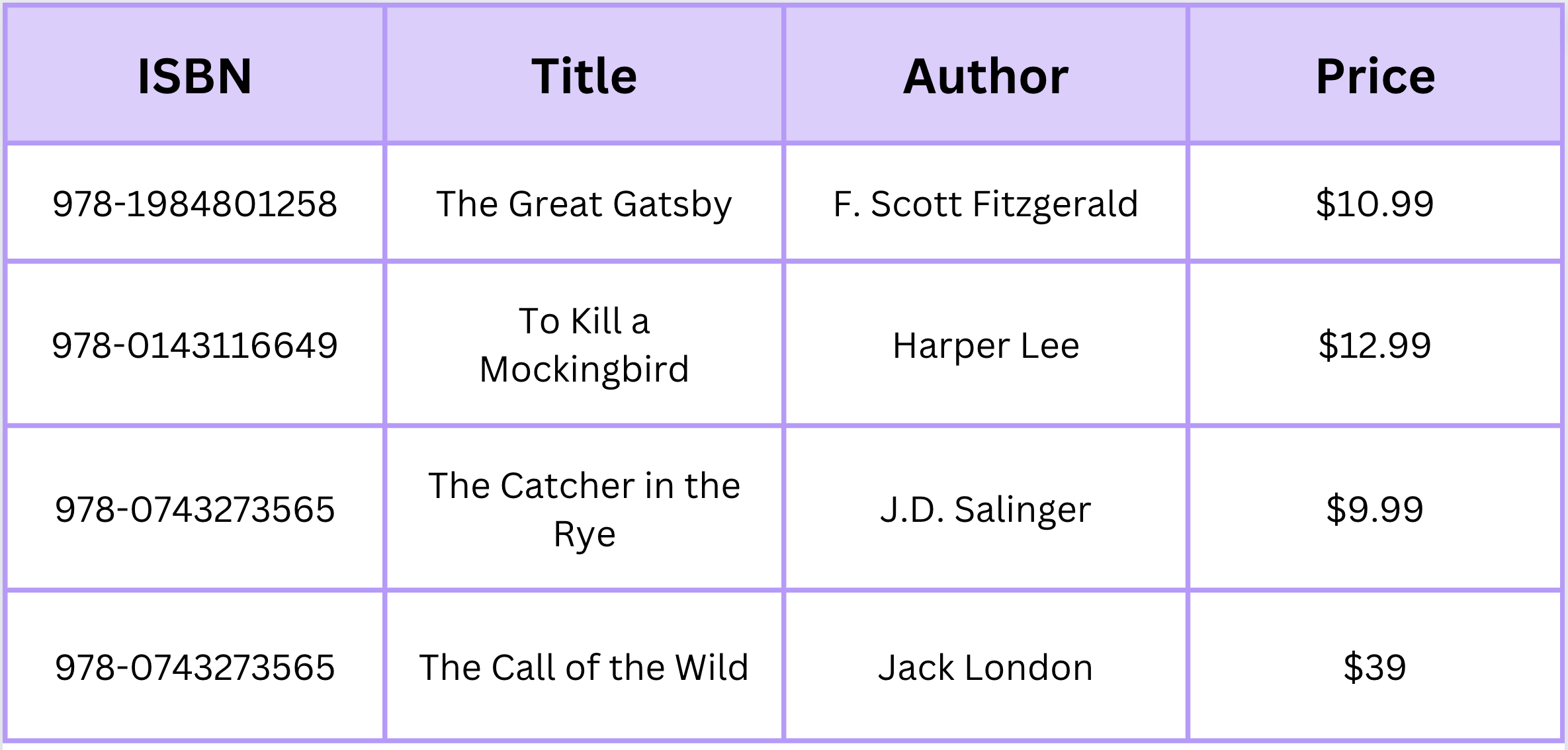
この例では、Booksは、各書籍の属性を表す特定の列を持つ表であり、各行は個別の書籍を表します。
3. リレーショナルデータベースにおけるデータモデリング
リレーショナルデータベースの設計において重要な側面であるデータモデリングは、データがデータベース内でどのように構造化、整理、および関連付けられるかを定義する設計図を作成することを含みます。このセクションでは、リレーショナルデータベースのコンテキストにおけるデータモデリングの概念を探求し、エンティティ関係図(ERD)の重要性を強調し、リレーショナルモデルに関連する重要な用語、制約、異常、コッドの規則、欠点、特性について説明します。
データモデリングの概念の説明
データモデリングは、リレーショナルデータベースが保存および管理するデータの構造を定義します。これは、現実世界のエンティティとデータベース内の表との間の橋渡しとしての役割を果たします。データモデリングは、データの明確で構造化された表現を作成することを目指し、情報が効率的かつ正確に整理されるようにします。
エンティティ関係図(ERD)の重要性
エンティティ関係図(ERD)は、データモデルの視覚的な表現です。エンティティ(データベースの表に対応)、属性(表の列に対応)、エンティティ間の関係を表すために、記号と表記を使用します。ERDは、データベースの構造を設計および伝達するための明確で直感的な方法を提供します。
重要な用語
-
エンティティ:エンティティは、顧客、製品、注文など、現実世界のオブジェクトまたは概念を表します。
-
属性:属性は、エンティティのプロパティまたは特性であり、どのような種類の情報が保存されるかを定義します。
-
関係:関係は、エンティティがお互いにどのように関連付けられているかを記述し、表間の接続を確立します。
リレーショナルモデルにおける制約
制約は、リレーショナルデータベース内のデータ整合性を確保する規則と条件です。一般的な制約には、以下が含まれます。
-
主キー:表の各レコードが一意であることを保証し、レコードを識別するために使用できます。
-
外部キー:別の表の主キーを参照することにより、表間の関係を確立します。
-
チェック制約:データが列に入力されるために満たす必要がある条件を指定します。
リレーショナルモデルにおける異常
異常は、設計不良が原因でリレーショナルデータベースに発生する可能性のある問題です。3つの主な種類の異常があります。
-
挿入異常:情報が不足しているため、データベースにデータを追加することが困難な場合に発生します。
-
更新異常:データを更新すると、不整合や不正確さが生じる場合に発生します。
-
削除異常:データを削除すると、意図せずに他の関連データが削除される場合に発生します。
リレーショナルモデルにおけるコッドの規則
コッドの規則は、リレーショナルモデルの発明者であるエドガー・F・コッドによって提案された一連のガイドラインです。これらの規則は、データベースが真のリレーショナルデータベースと見なされるために満たす必要がある特性と要件を定義しています。
- 規則1:情報規則 - データベースに保存されるデータは、ユーザーデータであろうとメタデータであろうと、ある表セルの値でなければなりません。データベース内のすべてのものは、テーブル形式で保存されなければなりません。
- 規則2:保証されたアクセス規則 - すべてのデータ要素(値)には、テーブル名、主キー(行値)、属性名(列値)の組み合わせを使用して論理的にアクセスすることが保証されています。ポインターなど、他の手段を使用してデータにアクセスすることはできません。
- 規則3:NULL値の体系的な処理 - データベース内のNULL値には、体系的で統一的な処理が与えられなければなりません。これは非常に重要な規則です。NULLは、次のいずれかとして解釈できるためです。データがありません、データは不明です、データは適用できません。
- 規則4:アクティブなオンラインカタログ - データベース全体の構造記述は、オンラインカタログ(データ辞書と呼ばれる)に保存され、権限のあるユーザーがアクセスできます。ユーザーは、データベース自体にアクセスするために使用するのと同じクエリ言語を使用してカタログにアクセスできます。
- 規則5:包括的なデータ副言語規則 - データベースには、データ定義、データ操作、トランザクション管理操作をサポートする線形構文を持つ言語のみを使用してアクセスできます。この言語は、直接使用するか、何らかのアプリケーションを介して使用できます。データベースがこの言語の助けなしにデータへのアクセスを許可する場合、それは違反と見なされます。
- 規則6:ビュー更新規則 - 理論的に更新できるデータベースのすべてのビューも、システムによって更新可能でなければなりません。
- 規則7:高レベルの挿入、更新、削除規則 - データベースは、高レベルの挿入、更新、削除をサポートする必要があります。これは単一行に限定されるべきではありません。つまり、データレコードのセットを生成するために、ユニオン、インターセクション、マイナス演算もサポートする必要があります。
- 規則8:物理データ独立性 - データベースに保存されているデータは、データベースにアクセスするアプリケーションとは独立している必要があります。データベースの物理構造の変更は、外部アプリケーションがデータにアクセスする方法に影響を与えてはなりません。
- 規則9:論理データ独立性 - データベース内の論理データは、ユーザーのビュー(アプリケーション)とは独立している必要があります。論理データの変更は、それを使用するアプリケーションに影響を与えてはなりません。たとえば、2つのテーブルがマージされた場合、または1つのテーブルが2つの異なるテーブルに分割された場合、ユーザーアプリケーションには影響や変更がありません。これは、適用が最も困難な規則の1つです。
- 規則10:整合性独立性 - データベースは、それを使用するアプリケーションとは独立している必要があります。その整合性制約はすべて、アプリケーションを変更する必要なしに独立して変更できます。この規則により、データベースはフロントエンドアプリケーションとそのインターフェースから独立します。
- 規則11:分散独立性 - エンドユーザーは、データがさまざまな場所に分散されていることがわかるべきではありません。ユーザーは常に、データが1つのサイトのみに存在するという印象を受ける必要があります。この規則は、分散データベースシステムの基礎と見なされてきました。
- 規則12:非転覆規則 - システムが低レベルのレコードへのアクセスを提供するインターフェースを持っている場合、そのインターフェースはシステムを転覆させ、セキュリティと整合性制約をバイパスすることはできません。
4. 正規化技法
正規化は、リレーショナルデータベース設計における基本的な概念であり、データの冗長性を削減し、データの整合性を確保することを目的としています。このセクションでは、正規化の概念、データベース設計における役割、および効率的で適切に構造化されたデータベースを実現するのに役立つさまざまな正規形(1NF~5NF)について探ります。また、提案されている6NFにも触れ、データベース正規化の例を示します。
正規化の概念の説明
正規化とは、リレーショナルデータベース内のデータを整理して、冗長性と依存性を最小限にするプロセスです。正規化の主な目標は、挿入、更新、削除の異常など、データベースの不整合や非効率につながるデータの異常を排除することです。
正規化は、大きな表を小さく関連する表に分割し、それらの間に関係を確立することによってこれを実現します。
さまざまな正規形(1NF~5NF)とその重要性
1NF(第一正規形)規則
- 原子値:表の各列には、原子(分割できない)値が含まれている必要があります。
- 一意の列名:各列には一意の名前が必要です。
- 順序付けられた行:表内の行の順序は重要ではありません。
2NF(第二正規形)規則
- 1NFを満たす必要があります。
- 部分従属がないこと:非キー属性(主キーの一部ではない属性)は、主キー全体に依存している必要があります。
3NF(第三正規形)規則
- 2NFを満たす必要があります。
- 推移従属がないこと:非キー属性は、他の非キー属性に依存してはなりません。
4NF(第四正規形)規則
- 3NFを満たす必要があります。
- 多値従属がないこと:属性間に多値従属があってはなりません。
5NF(第五正規形)規則
- 4NFを満たす必要があります。
- 結合従属がないこと:情報を取得するために複数の表を結合する必要があるような方法でデータが保存されてはなりません。
6NF(第六正規形)提案
6NFは、時間的および歴史的な側面を持つデータベースにおけるデータの表現を扱う、提案されているがそれほど一般的に使用されていない正規形です。
例を使ったデータベース正規化
正規化のプロセスを説明するために例を考えてみましょう。先に述べたbooks表の例に戻りましょう。
この表は、著者の情報が各書籍ごとに繰り返されているため、冗長性を示しています。この表を正規化するには、著者用の別の表を作成し、冗長性を排除し、関係を通じてデータの整合性を確保します。
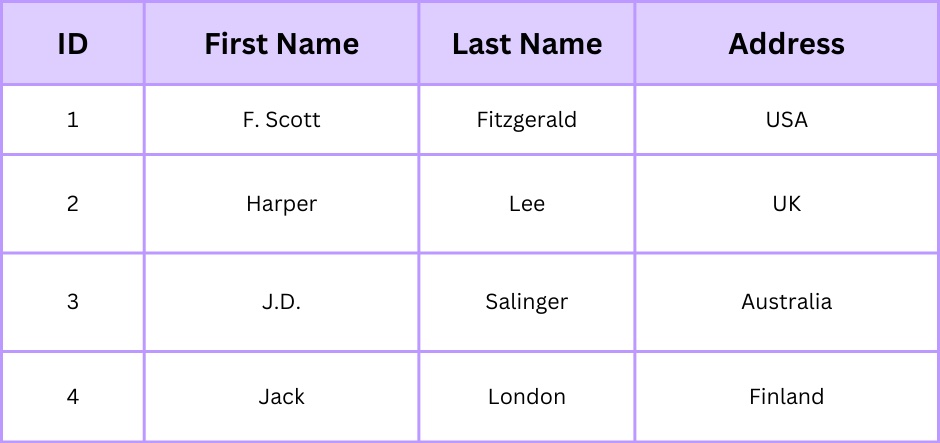
5. 構造化照会言語(SQL)
構造化照会言語(SQL)は、リレーショナルデータベースと対話するための標準言語です。これは、データベースと通信するための強力で汎用性の高い手段を提供し、ユーザーはデータの照会、挿入、更新、削除などの操作を実行できます。このセクションでは、SQLを紹介し、重要な用語を網羅し、基本的なSQLコマンドの概要を示します。
リレーショナルデータベースの言語としてのSQLの紹介
SQL(Structured Query Languageの略)は、リレーショナルデータベースシステムの管理と操作のために設計されたドメイン固有言語です。これは、ユーザーとデータベース間の橋渡しとしての役割を果たし、ユーザーは内部に保存されているデータと対話できます。
SQLは、以下のデータベース関連タスクに不可欠です。
- データ取得:特定の情報を取得するためにデータベースを照会します。
- データ変更:データベースのレコードを挿入、更新、または削除します。
- スキーマ管理:表、インデックス、その他のデータベース構造を作成、変更、または削除します。
- アクセス制御:ユーザーの権限とアクセス権を定義および管理します。
重要な用語
SQLコマンドに進む前に、いくつかの重要なSQL用語を理解しましょう。
- データベース:表、インデックス、その他の関連オブジェクトに整理されたデータの構造化されたコレクションです。
- 表:行と列にデータを保存する基本的なデータベースオブジェクトです。
- 行:表内の単一のレコードまたはデータエントリです。
- 列:特定の種類のデータを保存する表内の属性またはフィールドです。
- 主キー:表の各行の一意の識別子であり、データの整合性を確保します。
- 外部キー:ある表の列であり、別の表の主キーへのリンクを確立し、表間の関係を作成します。
- クエリ:1つ以上の表から特定のデータを取得するためにSQLで作成された要求です。
- SQL文:SELECT、INSERT、UPDATE、DELETEなど、特定の動作を実行する単一のSQLコマンドです。
基本的なSQLコマンドの概要
SQLコマンドは、その機能に基づいて大きく4つの主要なタイプに分類できます。
-
データクエリコマンド(SELECT):これらのコマンドは、データベース内の1つ以上の表からデータを取得するために使用されます。データ取得のための最も基本的なSQLコマンドはSELECT文です。たとえば:
SELECT * FROM Customers;
-
データ変更コマンド(INSERT、UPDATE、DELETE):これらのコマンドは、データベースのデータの挿入、更新、または削除に使用されます。たとえば:
INSERT INTO Orders (OrderID, CustomerID, OrderDate) VALUES (1, 101, '2023-09-06');UPDATE Products SET Price = 1500 WHERE ProductID = 101;DELETE FROM Customers WHERE CustomerID = 201;
-
データ定義コマンド(CREATE、ALTER、DROP):これらのコマンドは、表やインデックスなど、データベースオブジェクトの構造を定義および管理するために使用されます。たとえば:
CREATE TABLE Employees (EmployeeID INT, FirstName VARCHAR(50), LastName VARCHAR(50));ALTER TABLE Customers ADD Email VARCHAR(100);DROP TABLE Products;
-
データ制御コマンド(GRANT、REVOKE):これらのコマンドは、データベースオブジェクトへのユーザーアクセスと権限を管理するために使用されます。たとえば:
GRANT SELECT ON Customers TO UserA;REVOKE INSERT ON Orders FROM UserB;
SQLの汎用性と表現力により、リレーショナルデータベースを扱うすべての人にとって重要なツールとなっています。この記事の次のセクションでは、結合、サブクエリ、さまざまなデータ操作技法など、高度なSQL操作をさらに詳しく調べ、それらの使用方法を示す実践的な例を示します。
6. 高度なSQL操作
このセクションでは、より高い精度と複雑さでリレーショナルデータベースを操作および照会できるようにする、高度なSQL操作をさらに詳しく調べます。これらの高度な操作には、結合、サブクエリ、ウィンドウ関数、集計、共通テーブル式(CTE)、再帰的CTE、一時関数、データピボット、Except対Not In、自己結合、ランキング関数、デルタ値の計算、実行合計の計算、日時操作が含まれます。これらの操作をそれぞれ説明するために、実践的な例を示します。
結合
結合を使用すると、共通の列に基づいて複数の表のデータを組み合わせることができます。INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL OUTER JOINなど、さまざまな種類の結合があります。INNER JOINの例を次に示します。
SELECT Orders.OrderID, Customers.CustomerName FROM Orders INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
サブクエリ
サブクエリは、メインクエリ内のネストされたクエリです。メインクエリの条件で使用されるデータを検索するために使用されます。たとえば:
SELECT ProductName FROM Products WHERE SupplierID IN (SELECT SupplierID FROM Suppliers WHERE Country = 'USA');
ウィンドウ関数
ウィンドウ関数は、現在の行に関連する表の行のセット全体で計算を実行します。これらは、ランキング、集計、移動平均の計算によく使用されます。RANK()ウィンドウ関数を使用した例を次に示します。
SELECT ProductName, Category, Price, RANK() OVER (PARTITION BY Category ORDER BY Price) AS Rank FROM Products;
集計
集計を使用すると、行のグループに対して計算を実行できます。これは、GROUP BYと共に使用されることがよくあります。たとえば:
SELECT Category, AVG(Price) AS AveragePrice FROM Products GROUP BY Category;
共通テーブル式(CTE)
共通テーブル式(CTE)は、複雑なクエリの一時的な結果セットを作成する方法を提供します。例を次に示します。
WITH TopCustomers AS ( SELECT CustomerID, COUNT(OrderID) AS OrderCount FROM Orders GROUP BY CustomerID HAVING COUNT(OrderID) > 5 ) SELECT Customers.CustomerName, TopCustomers.OrderCount FROM Customers INNER JOIN TopCustomers ON Customers.CustomerID = TopCustomers.CustomerID;
再帰的CTE
再帰的CTEは、階層データの処理に使用されます。これにより、CTE自体を参照できます。例としては、組織の階層を表すことが考えられます。
WITH expression_name (column_list) AS ( -- アンカーメンバー initial_query UNION ALL -- expression_nameを参照する再帰メンバー。 recursive_query ) -- expression nameを参照 SELECT * FROM expression_name
一時関数
一時関数は、SQLクエリで使用できるユーザー定義関数です。これにより、複雑なロジックをカプセル化し、クエリ全体で再利用できます。
CREATE OR REPLACE FUNCTION get_discounted_price(product_id INT)
RETURNS NUMERIC(10, 2)
AS
$$
DECLARE
original_price NUMERIC(10, 2);
discount_rate NUMERIC(5, 2);
discounted_price NUMERIC(10, 2);
BEGIN
SELECT price, discount INTO original_price, discount_rate
FROM Products
WHERE product_id = product_id;
discounted_price := original_price * (1 - discount_rate);
RETURN discounted_price;
END;
$$
LANGUAGE plpgsql;
CASE WHENを使用したデータのピボット
データのピボットには、行を列に変換するか、その逆に変換することが含まれます。この目的にはCASE WHEN文を使用できます。
SELECT
name,
SUM(CASE WHEN val = 1 THEN amount ELSE 0 END) AS amountVal1,
SUM(CASE WHEN val = 2 THEN amount ELSE 0 END) AS amountVal2
FROM bank GROUP BY name
Except対Not In
EXCEPTとNOT INは、2つのデータセットの違いを見つけるために使用されます。EXCEPTは、右側のクエリに表示されない左側のクエリからの異なる行を返します。
USE BookStore
SELECT id, name, category, price FROM Books1
WHERE id NOT IN (SELECT id from Books2)
自己結合
自己結合は、表がそれ自体と結合される場合に発生します。これらは、階層データの処理時、または同じ表内のレコードを関連付ける必要がある場合に役立ちます。
SELECT A.CustomerName AS CustomerName1, B.CustomerName AS CustomerName2, A.City
FROM Customers A, Customers B
WHERE A.CustomerID <> B.CustomerID
AND A.City = B.City
ORDER BY A.City;
Rank対Dense Rank対Row Number
ランク関数は、指定された列に基づいて各行にランクを割り当てます。RANK()は重複したランクを許可しますが、DENSE_RANK()は重複する値に連続したランクを割り当てます。ROW_NUMBER()は各行に一意の行番号を割り当てます。
SELECT *, ROW_NUMBER() OVER(ORDER BY employee_name) AS rownumber FROM employees
SELECT employee_name, employee_salary, RANK() OVER(ORDER BY employee_name) AS rank_id FROM employees
SELECT employee_name ,employee_salary ,DENSE_RANK() OVER(ORDER BY employee_name) AS rank_id FROM employees
デルタ値の計算
デルタ値の計算には、データセット内の連続する行間の差を求めることが含まれます。これは、時間の経過に伴う変化を識別する場合に役立ちます。
SELECT
city,
year,
population_needing_house,
LAG(population_needing_house)
OVER (PARTITION BY city ORDER BY year ) AS previous_year,
population_needing_house - LAG(population_needing_house)
OVER (PARTITION BY city ORDER BY year ) AS difference_previous_year
FROM housing
ORDER BY city, year
日時操作
SQLは、DATEADD、DATEDIFF、DATEPARTなど、日付と時刻のデータを操作およびフォーマットするためのさまざまな日付と時刻の関数を提供しています。
これらの高度なSQL操作は、リレーショナルデータベースのデータの照会と分析のための強力なツールを提供し、複雑なタスクに取り組み、データから貴重な洞察を抽出できます。各操作は特定の目的を果たしており、それらを習得することで、データベースを効果的に操作する能力を大幅に向上させることができます。
7. リレーショナルデータベース管理システム(RDBMS)
リレーショナルデータベース管理システム(RDBMS)は、リレーショナルデータベースを効率的に管理するために必要なツールとサービスを提供するソフトウェアアプリケーションです。このセクションでは、一般的なRDBMSオプションとその独自の機能を紹介します。また、特定のユースケースに適したRDBMSを選択することの重要性も強調します。
一般的なRDBMSオプション
-
- オープンソース:MySQLは、オープンソースであることで知られており、幅広いユーザーや開発者がアクセスできます。




