
Pythonによる音声テキスト変換:ツール、コード、比較
By manhnv, at: 2024年11月26日11:17
予想読書時間: __READING_TIME__ 分


音声テキスト変換は、パーソナルアシスタントから転写ツールまで、多くのアプリケーションにおいて重要な機能です。この記事では、Pythonで音声テキスト変換を実装するための主要なライブラリとサービスについて解説します:SpeechRecognition、Google Cloud Speech-to-Text、Azure Speech Service、そしてWhisper by OpenAI。それぞれのサンプルコードを示し、パフォーマンス、精度、価格を比較します。
1. SpeechRecognition
概要
- 種類: オープンソース
- 依存関係: ローカルマイクまたは事前に録音されたオーディオファイル
- バックエンド: デフォルトではGoogle Web Speech API
- 用途: クイックプロトタイピング、趣味プロジェクト
コードスニペット
import speech_recognition as sr
recognizer = sr.Recognizer()
with sr.Microphone() as source:
print("聴取中...")
audio = recognizer.listen(source)
try:
text = recognizer.recognize_google(audio)
print("あなたは言いました:", text)
except sr.UnknownValueError:
print("音声内容を理解できませんでした。")
except sr.RequestError as e:
print(f"APIエラー: {e}")
2. Google Cloud Speech-to-Text
概要
- 種類: クラウドベースAPI
- 依存関係: Google Cloudアカウント
- 用途: 高精度、多様な言語サポート
コードスニペット
from google.cloud import speech
import io
client = speech.SpeechClient()
with io.open("audio.wav", "rb") as audio_file:
content = audio_file.read()
audio = speech.RecognitionAudio(content=content)
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
language_code="en-US",
)
response = client.recognize(config=config, audio=audio)
for result in response.results:
print("トランスクリプト:", result.alternatives[0].transcript)
3. Azure Speech Service
概要
- 種類: クラウドベースAPI
- 依存関係: Azure Cognitive Servicesアカウント
- 用途: エンタープライズアプリケーション、Microsoftエコシステムとの統合
コードスニペット
import azure.cognitiveservices.speech as speechsdk
speech_key = "YOUR_AZURE_SPEECH_KEY"
service_region = "YOUR_SERVICE_REGION"
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region)
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
print("何か話してください...")
result = speech_recognizer.recognize_once()
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("認識されました:", result.text)
else:
print("エラー:", result.reason)
4. Whisper by OpenAI
概要
- 種類: オープンソース、オフライン
- 依存関係: 事前学習済みWhisperモデル
- 用途: オフライン転写、様々なアクセントに対する高精度
コードスニペット
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print("転写:", result["text"])
比較表
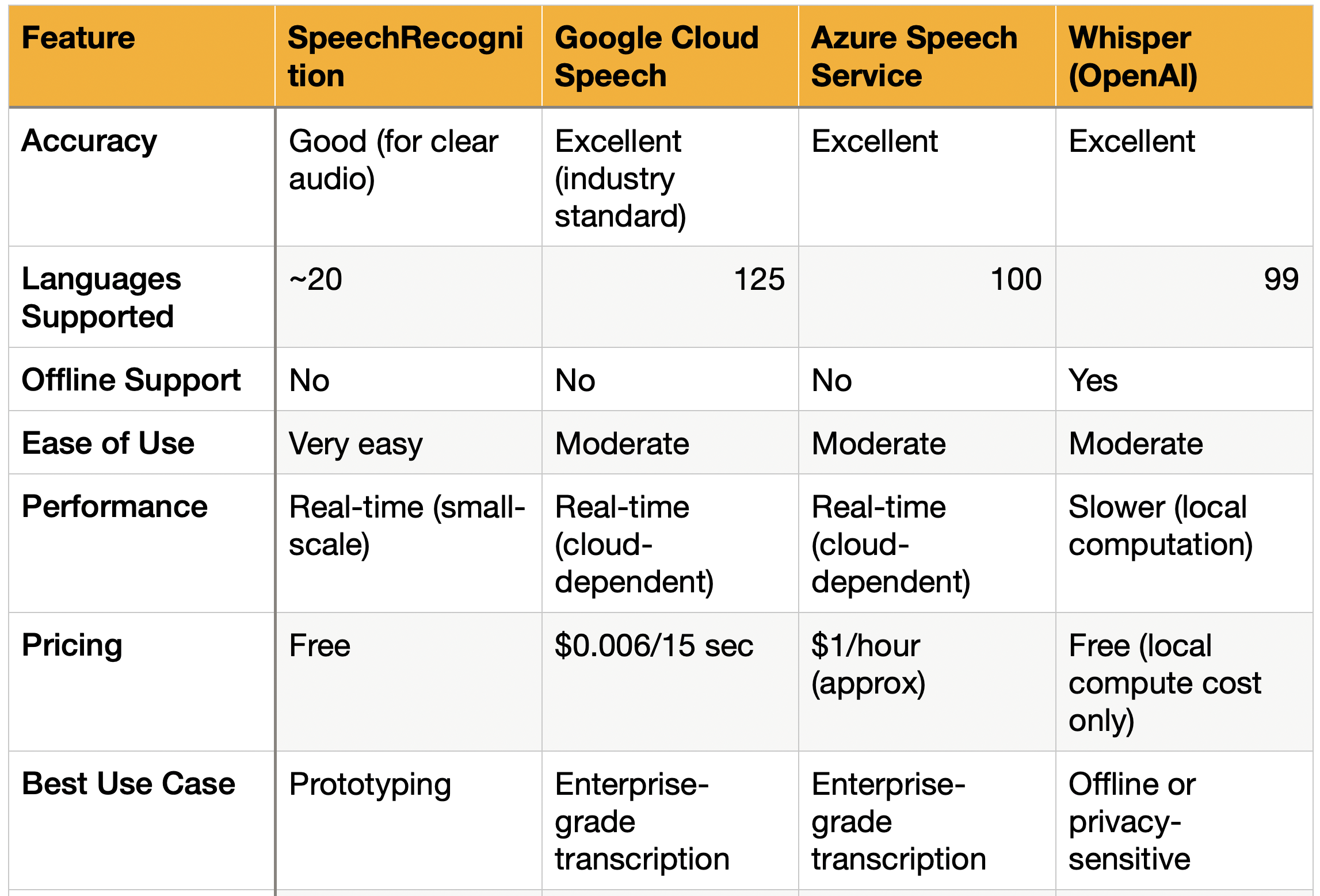
パフォーマンスに関する考察
-
精度:
- WhisperとGoogle Cloud Speechは、様々なアクセントやノイズのある環境において優れた精度を提供します。
- SpeechRecognitionは、不明瞭な音声で苦労する可能性があります。
- WhisperとGoogle Cloud Speechは、様々なアクセントやノイズのある環境において優れた精度を提供します。
-
速度:
- SpeechRecognitionとGoogleやAzureのようなクラウドサービスは、特にリアルタイムタスクにおいてWhisperよりも高速です。
- Whisperは速度は遅いですが、オフラインで動作するため、プライバシー重視のアプリケーションに役立ちます。
- SpeechRecognitionとGoogleやAzureのようなクラウドサービスは、特にリアルタイムタスクにおいてWhisperよりも高速です。
-
コスト:
- SpeechRecognitionとWhisperは、小規模なプロジェクトに費用対効果が高いです。
- クラウドサービス(GoogleとAzure)は大規模で高精度のニーズには優れていますが、継続的なコストがかかります。
- SpeechRecognitionとWhisperは、小規模なプロジェクトに費用対効果が高いです。
最終的な推奨事項
- 迅速で小規模なプロジェクトにはSpeechRecognitionを使用してください。
- 高精度と言語サポートが必要なエンタープライズアプリケーションには、Google Cloud SpeechまたはAzure Speech Serviceを選択してください。
- オフライン機能またはプライバシーが優先事項の場合は、Whisperを選択してください。
![[TIPS] Python Argument Parser - Bad Practices](/media/filer_public_thumbnails/filer_public/7d/65/7d65d4a7-db1f-409a-bf38-624b253933a7/tips_python_argument_parser_-_bad_practices.png__400x240_q85_crop_subsampling-2_upscale.jpg)



