
Cơ sở dữ liệu quan hệ: Từ nền tảng cơ bản đến xu hướng và đổi mới trong tương lai
By JoeVu, at: 17:06 Ngày 06 tháng 9 năm 2023
Thời gian đọc ước tính: __READING_TIME__ phút


1. Giới thiệu
Trong thời đại kỹ thuật số, dữ liệu được tạo ra và tiêu thụ với tốc độ chưa từng có, vai trò của cơ sở dữ liệu trong việc quản lý nguồn tài nguyên quý giá này không thể được đánh giá quá cao. Trong số các mô hình cơ sở dữ liệu khác nhau, cơ sở dữ liệu quan hệ nổi bật như nền tảng của các hệ thống quản lý dữ liệu hiện đại. Chúng cung cấp phương tiện có cấu trúc và hiệu quả để tổ chức, lưu trữ và truy xuất dữ liệu. Bài viết này bắt đầu một hành trình khám phá những nguyên tắc cơ bản của cơ sở dữ liệu quan hệ, đi sâu vào các khái niệm thiết yếu như mô hình hóa dữ liệu, Ngôn ngữ truy vấn có cấu trúc (SQL), kỹ thuật chuẩn hóa và hơn thế nữa.
Lịch sử ngắn gọn về Cơ sở dữ liệu
Để đánh giá tầm quan trọng của cơ sở dữ liệu quan hệ, điều hữu ích là nhìn lại quá trình phát triển lịch sử của chúng. Cơ sở dữ liệu, ở một hình thức nào đó, đã tồn tại từ những ngày đầu của máy tính. Tuy nhiên, sự ra đời của mô hình cơ sở dữ liệu quan hệ có thể được truy ngược lại đến những năm 1970 khi nhà khoa học máy tính Edgar F. Codd đã giới thiệu khái niệm đột phá này.
Ý tưởng của Codd rất đơn giản nhưng mang tính cách mạng: tổ chức dữ liệu thành các bảng bao gồm các hàng và cột, và thiết lập mối quan hệ giữa các bảng này. Sự đổi mới này đã mở đường cho một cách tiếp cận trực quan hơn và có cấu trúc hơn đối với việc lưu trữ và truy xuất dữ liệu. Sự thanh lịch và hiệu quả của mô hình cơ sở dữ liệu quan hệ nhanh chóng được đón nhận, biến nó trở thành nền tảng mà nhiều ứng dụng và hệ thống dựa trên dữ liệu ngày nay được xây dựng.
Lợi ích chính
-
Lưu trữ dữ liệu có cấu trúc: tổ chức dữ liệu thành các bảng có cấu trúc, đảm bảo tính toàn vẹn và nhất quán của dữ liệu.
-
Toàn vẹn dữ liệu: Chúng thực thi các ràng buộc toàn vẹn dữ liệu, chẳng hạn như khóa chính và khóa ngoại, để duy trì độ chính xác và độ tin cậy của dữ liệu.
-
Truy vấn linh hoạt: SQL, ngôn ngữ truy vấn dành cho cơ sở dữ liệu quan hệ, cung cấp một cách mạnh mẽ và linh hoạt để truy xuất và thao tác dữ liệu.
-
Khả năng mở rộng: Nhiều hệ quản trị cơ sở dữ liệu quan hệ (RDBMS) cung cấp các tùy chọn khả năng mở rộng, cho phép các doanh nghiệp xử lý hiệu quả các tập dữ liệu ngày càng tăng.
-
Thuộc tính ACID: tuân thủ các thuộc tính ACID (Nguyên tử, Nhất quán, Cách ly, Bền bỉ), đảm bảo độ tin cậy của giao dịch.
Nhược điểm
-
Sơ đồ cố định: yêu cầu một sơ đồ được xác định trước, khiến việc thích ứng với các cấu trúc dữ liệu thay đổi nhanh chóng trở nên khó khăn.
-
Khả năng mở rộng hiệu suất: Việc mở rộng cơ sở dữ liệu quan hệ theo chiều ngang có thể phức tạp và tốn kém, hạn chế khả năng xử lý khối lượng dữ liệu và lưu lượng truy cập lớn.
-
Độ phức tạp: Thiết kế và bảo trì cơ sở dữ liệu quan hệ có thể phức tạp, đặc biệt là đối với các tập dữ liệu lớn và phức tạp.
-
Chi phí chuẩn hóa: Mặc dù chuẩn hóa làm giảm sự dư thừa, nhưng nó có thể làm tăng độ phức tạp trong hiệu suất truy vấn do nhiều thao tác nối bảng.
-
Khóa nhà cung cấp: Việc chọn một RDBMS cụ thể có thể dẫn đến việc khóa nhà cung cấp, khiến việc di chuyển sang các hệ thống khác trở nên khó khăn.
2. Cơ sở dữ liệu quan hệ là gì?
Cơ sở dữ liệu quan hệ là một thành phần cơ bản của các hệ thống quản lý dữ liệu hiện đại, được biết đến với phương pháp tiếp cận có cấu trúc và hiệu quả đối với việc tổ chức dữ liệu. Trong phần này, chúng ta sẽ khám phá các nguyên tắc cốt lõi của cơ sở dữ liệu quan hệ, các thành phần chính của chúng và tầm quan trọng của chúng trong thế giới quản lý dữ liệu.
Định nghĩa và các thành phần chính
Về cơ bản, cơ sở dữ liệu quan hệ là một tập hợp dữ liệu được tổ chức thành các bảng. Các bảng này bao gồm các hàng và cột, trong đó mỗi hàng đại diện cho một bản ghi hoặc mục nhập duy nhất, và mỗi cột đại diện cho một thuộc tính hoặc trường cụ thể của bản ghi đó.
Các thành phần chính:
- Bảng: Đơn vị tổ chức cơ bản trong cơ sở dữ liệu quan hệ.
- Hàng: Mỗi hàng đại diện cho một bản ghi, thực thể hoặc điểm dữ liệu duy nhất.
- Cột: Các cột xác định các thuộc tính hoặc đặc điểm của dữ liệu được lưu trữ trong bảng.
- Khóa: Khóa, chẳng hạn như khóa chính và khóa ngoại, thiết lập mối quan hệ giữa các bảng.
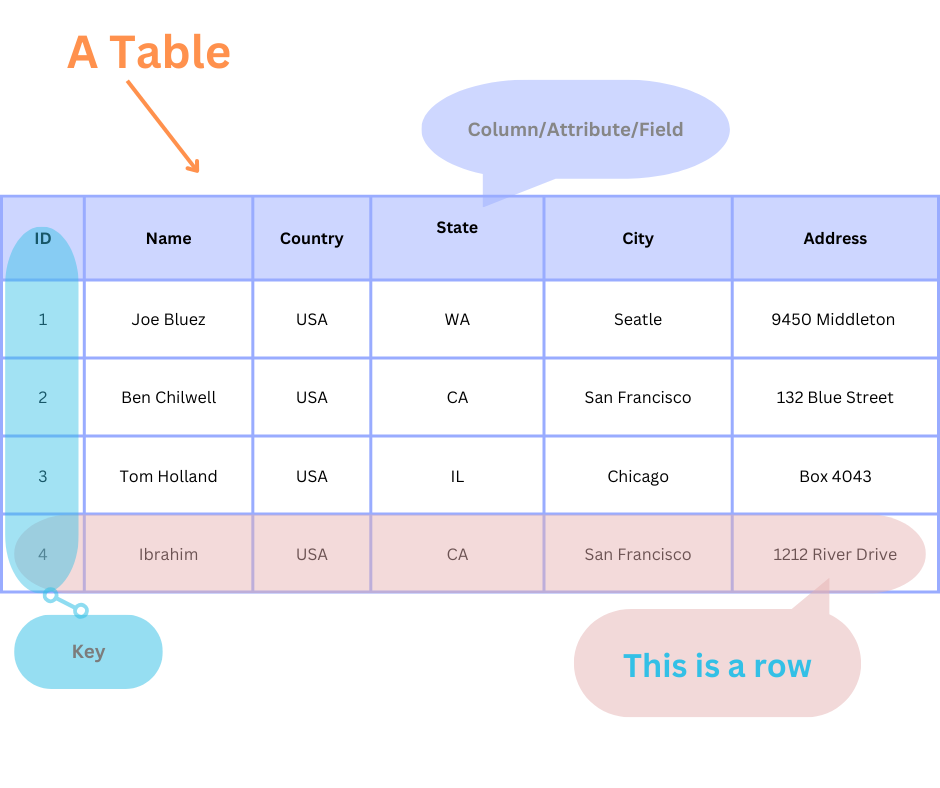
Ví dụ về Cơ sở dữ liệu quan hệ
Hãy minh họa điều này bằng một ví dụ đơn giản. Giả sử chúng ta đang quản lý dữ liệu cho một hiệu sách trực tuyến. Chúng ta có thể có một bảng "Sách" với các cột như "ISBN", "Tiêu đề", "Tác giả" và "Giá". Mỗi hàng trong bảng này đại diện cho một mục nhập sách duy nhất.
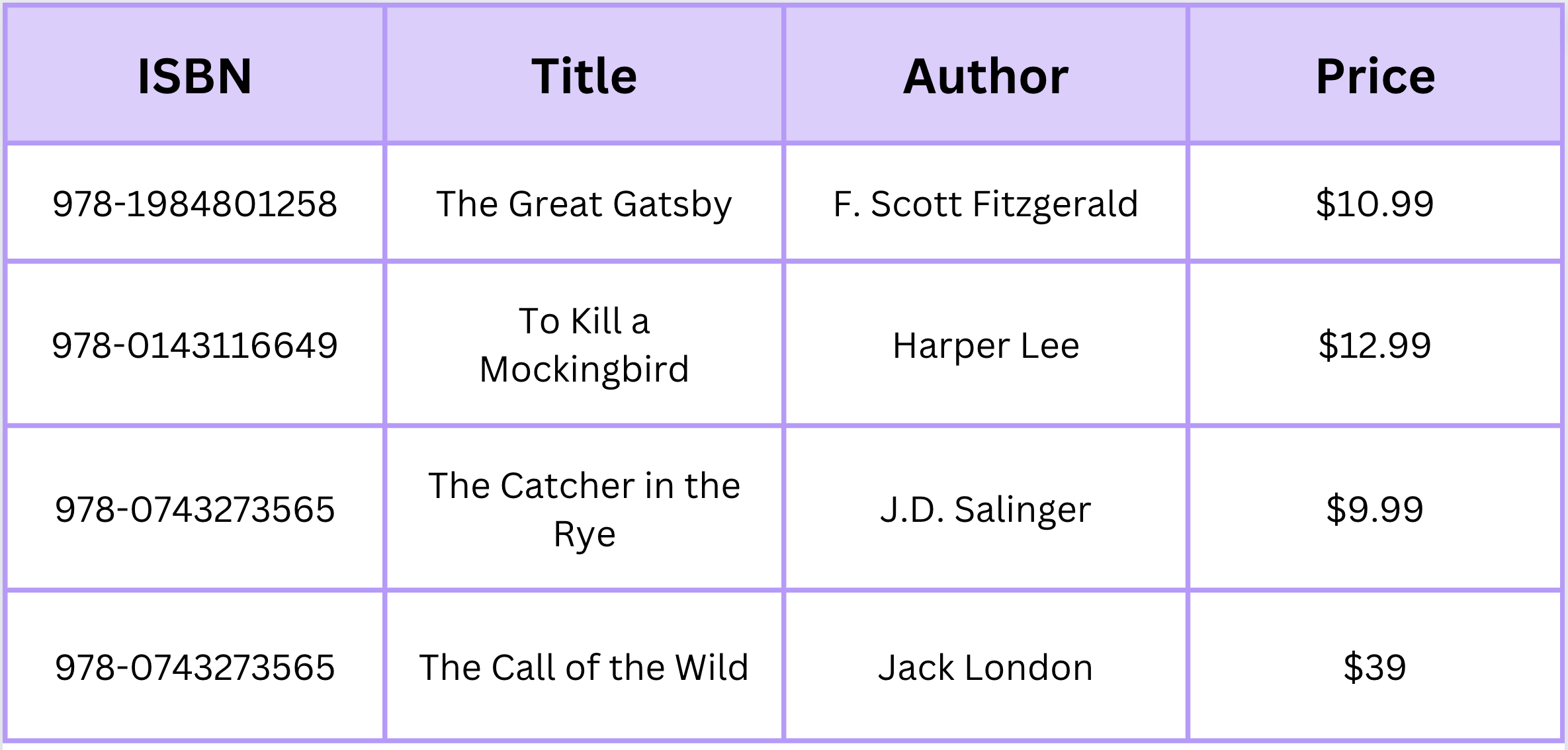
Trong ví dụ này, Sách là một bảng với các cột cụ thể đại diện cho các thuộc tính của mỗi cuốn sách, và mỗi hàng đại diện cho một cuốn sách riêng biệt.
3. Mô hình hóa dữ liệu trong Cơ sở dữ liệu quan hệ
Mô hình hóa dữ liệu, một khía cạnh quan trọng trong việc thiết kế cơ sở dữ liệu quan hệ, bao gồm việc tạo ra một bản thiết kế xác định cách dữ liệu sẽ được cấu trúc, tổ chức và liên kết trong cơ sở dữ liệu. Trong phần này, chúng ta sẽ khám phá khái niệm mô hình hóa dữ liệu trong ngữ cảnh của cơ sở dữ liệu quan hệ, làm nổi bật tầm quan trọng của Biểu đồ Quan hệ Thực thể (ERD) và thảo luận về các thuật ngữ chính, ràng buộc, bất thường, quy tắc của Codd, nhược điểm và đặc điểm liên quan đến mô hình quan hệ.
Giải thích khái niệm Mô hình hóa dữ liệu
Mô hình hóa dữ liệu xác định cấu trúc của dữ liệu mà cơ sở dữ liệu quan hệ sẽ lưu trữ và quản lý. Nó đóng vai trò như một cầu nối giữa các thực thể trong thế giới thực và các bảng trong cơ sở dữ liệu. Mô hình hóa dữ liệu nhằm mục đích tạo ra một biểu diễn dữ liệu rõ ràng và có cấu trúc, đảm bảo thông tin được tổ chức hiệu quả và chính xác.
Tầm quan trọng của Biểu đồ Quan hệ Thực thể (ERD)
Biểu đồ Quan hệ Thực thể (ERD) là một biểu diễn trực quan của mô hình dữ liệu. Chúng sử dụng các ký hiệu và chú thích để mô tả các thực thể (tương ứng với các bảng cơ sở dữ liệu), thuộc tính (tương ứng với các cột bảng) và mối quan hệ giữa các thực thể. ERD cung cấp một cách rõ ràng và trực quan để thiết kế và truyền đạt cấu trúc của cơ sở dữ liệu.
Các thuật ngữ quan trọng
-
Thực thể: Thực thể đại diện cho các đối tượng hoặc khái niệm trong thế giới thực, chẳng hạn như khách hàng, sản phẩm hoặc đơn đặt hàng.
-
Thuộc tính: Thuộc tính là các đặc điểm hoặc đặc tính của thực thể, xác định loại thông tin được lưu trữ.
-
Mối quan hệ: Mối quan hệ mô tả cách các thực thể liên quan đến nhau, thiết lập kết nối giữa các bảng.
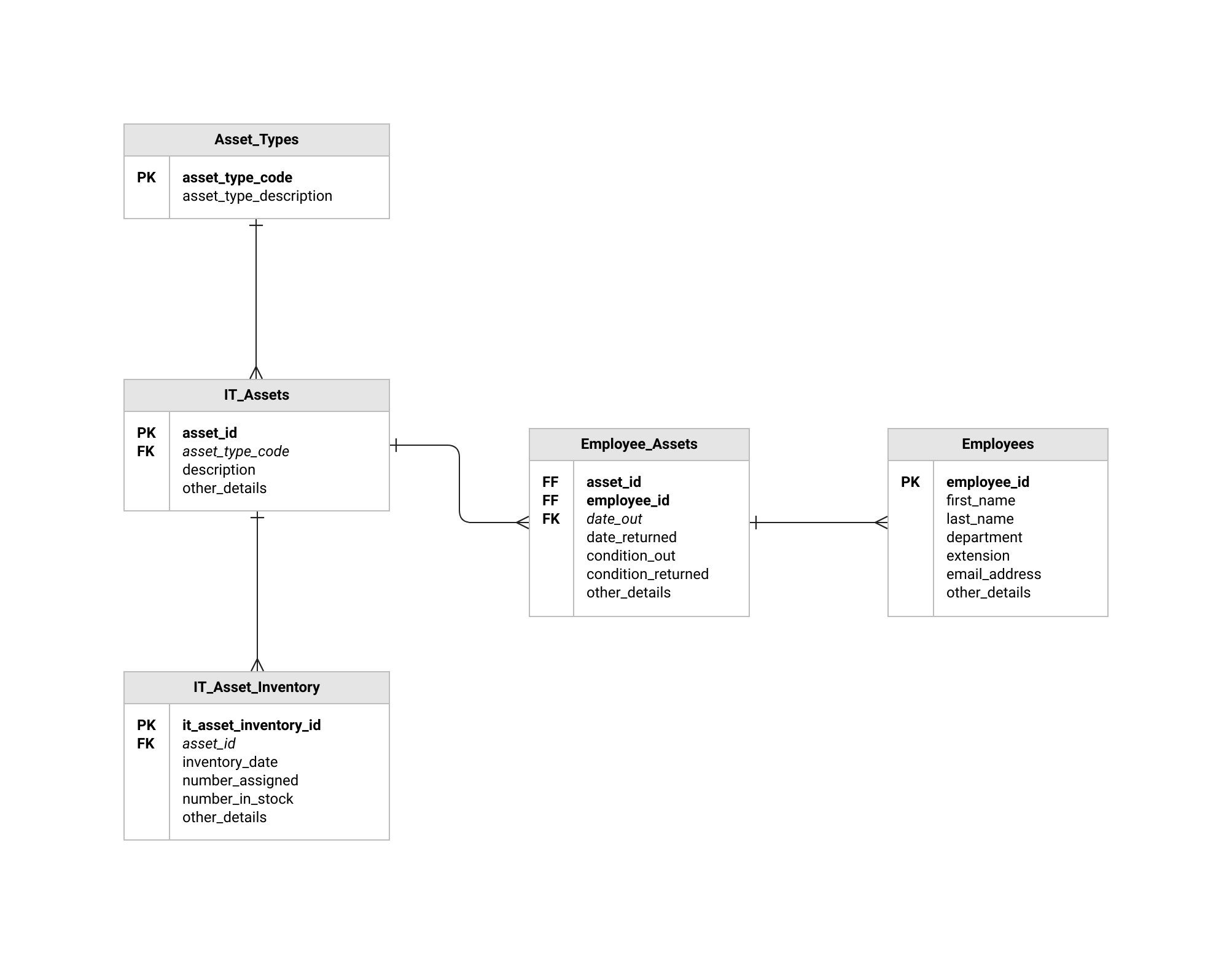
Ràng buộc trong Mô hình Quan hệ
Ràng buộc là các quy tắc và điều kiện đảm bảo tính toàn vẹn dữ liệu trong cơ sở dữ liệu quan hệ. Một số ràng buộc phổ biến bao gồm:
-
Khóa chính: Đảm bảo mỗi bản ghi trong bảng là duy nhất và có thể được sử dụng để xác định bản ghi.
-
Khóa ngoại: Thiết lập mối quan hệ giữa các bảng bằng cách tham chiếu khóa chính của bảng khác.
-
Ràng buộc kiểm tra: Chỉ định một điều kiện mà dữ liệu phải đáp ứng để được nhập vào một cột.
Bất thường trong Mô hình Quan hệ
Bất thường là các vấn đề có thể phát sinh trong cơ sở dữ liệu quan hệ do thiết kế kém. Ba loại bất thường chính là:
-
Bất thường chèn: Xảy ra khi khó thêm dữ liệu vào cơ sở dữ liệu vì thiếu thông tin.
-
Bất thường cập nhật: Xảy ra khi cập nhật dữ liệu dẫn đến sự không nhất quán hoặc thiếu chính xác.
-
Bất thường xóa: Phát sinh khi xóa dữ liệu vô tình xóa các dữ liệu liên quan khác.
Quy tắc của Codd trong Mô hình Quan hệ
Quy tắc của Codd là một tập hợp các hướng dẫn được đề xuất bởi Edgar F. Codd, người phát minh ra mô hình quan hệ. Các quy tắc này xác định các đặc điểm và yêu cầu mà cơ sở dữ liệu phải đáp ứng để được coi là một cơ sở dữ liệu quan hệ thực sự.
- Quy tắc 1: Quy tắc thông tin - Dữ liệu được lưu trữ trong cơ sở dữ liệu, dù là dữ liệu người dùng hay siêu dữ liệu, phải là giá trị của một ô bảng nào đó. Mọi thứ trong cơ sở dữ liệu phải được lưu trữ ở định dạng bảng.
- Quy tắc 2: Quy tắc truy cập được đảm bảo - Mỗi phần tử dữ liệu (giá trị) được đảm bảo truy cập logic bằng tổ hợp tên bảng, khóa chính (giá trị hàng) và tên thuộc tính (giá trị cột). Không có phương tiện nào khác, chẳng hạn như con trỏ, có thể được sử dụng để truy cập dữ liệu.
- Quy tắc 3: Xử lý có hệ thống các giá trị NULL - Các giá trị NULL trong cơ sở dữ liệu phải được xử lý có hệ thống và thống nhất. Đây là một quy tắc rất quan trọng vì một giá trị NULL có thể được hiểu là một trong những điều sau - dữ liệu bị thiếu, dữ liệu không được biết đến hoặc dữ liệu không áp dụng.
- Quy tắc 4: Danh mục trực tuyến hoạt động - Mô tả cấu trúc của toàn bộ cơ sở dữ liệu phải được lưu trữ trong một danh mục trực tuyến, được gọi là từ điển dữ liệu, có thể được truy cập bởi người dùng được ủy quyền. Người dùng có thể sử dụng cùng một ngôn ngữ truy vấn để truy cập danh mục mà họ sử dụng để truy cập chính cơ sở dữ liệu.
- Quy tắc 5: Quy tắc ngôn ngữ con dữ liệu toàn diện - Cơ sở dữ liệu chỉ có thể được truy cập bằng một ngôn ngữ có cú pháp tuyến tính hỗ trợ các thao tác định nghĩa dữ liệu, thao tác dữ liệu và quản lý giao dịch. Ngôn ngữ này có thể được sử dụng trực tiếp hoặc thông qua một số ứng dụng. Nếu cơ sở dữ liệu cho phép truy cập dữ liệu mà không cần sự trợ giúp của ngôn ngữ này, thì nó được coi là vi phạm.
- Quy tắc 6: Quy tắc cập nhật xem - Tất cả các chế độ xem của cơ sở dữ liệu, về mặt lý thuyết có thể được cập nhật, cũng phải được hệ thống cập nhật.
- Quy tắc 7: Quy tắc chèn, cập nhật và xóa cấp cao - Cơ sở dữ liệu phải hỗ trợ việc chèn, cập nhật và xóa cấp cao. Điều này không được giới hạn ở một hàng duy nhất, nghĩa là nó cũng phải hỗ trợ các phép toán hợp nhất, giao và trừ để tạo ra các tập hợp các bản ghi dữ liệu.
- Quy tắc 8: Độc lập dữ liệu vật lý - Dữ liệu được lưu trữ trong cơ sở dữ liệu phải độc lập với các ứng dụng truy cập cơ sở dữ liệu. Bất kỳ thay đổi nào trong cấu trúc vật lý của cơ sở dữ liệu đều không ảnh hưởng đến cách dữ liệu được truy cập bởi các ứng dụng bên ngoài.
- Quy tắc 9: Độc lập dữ liệu logic - Dữ liệu logic trong cơ sở dữ liệu phải độc lập với chế độ xem của người dùng (ứng dụng). Bất kỳ thay đổi nào trong dữ liệu logic đều không ảnh hưởng đến các ứng dụng đang sử dụng nó. Ví dụ: nếu hai bảng được hợp nhất hoặc một bảng bị chia thành hai bảng khác nhau, sẽ không có tác động hoặc thay đổi nào đối với ứng dụng của người dùng. Đây là một trong những quy tắc khó áp dụng nhất.
- Quy tắc 10: Độc lập toàn vẹn - Cơ sở dữ liệu phải độc lập với ứng dụng sử dụng nó. Tất cả các ràng buộc toàn vẹn của nó có thể được sửa đổi độc lập mà không cần bất kỳ thay đổi nào trong ứng dụng. Quy tắc này làm cho cơ sở dữ liệu độc lập với ứng dụng giao diện người dùng và giao diện của nó.
- Quy tắc 11: Độc lập phân phối - Người dùng cuối không được nhìn thấy dữ liệu được phân phối trên nhiều vị trí khác nhau. Người dùng luôn luôn có cảm giác rằng dữ liệu chỉ nằm ở một địa điểm duy nhất. Quy tắc này được coi là nền tảng của các hệ thống cơ sở dữ liệu phân tán.
- Quy tắc 12: Quy tắc không phá hoại - Nếu một hệ thống có giao diện cung cấp quyền truy cập vào các bản ghi cấp thấp, thì giao diện đó không được phép phá hoại hệ thống và bỏ qua các ràng buộc bảo mật và toàn vẹn.
4. Kỹ thuật chuẩn hóa
Chuẩn hóa là một khái niệm cơ bản trong thiết kế cơ sở dữ liệu quan hệ, nhằm mục đích giảm sự dư thừa dữ liệu và đảm bảo tính toàn vẹn dữ liệu. Trong phần này, chúng ta sẽ khám phá khái niệm chuẩn hóa, vai trò của nó trong thiết kế cơ sở dữ liệu và các dạng chuẩn khác nhau (từ 1NF đến 5NF) giúp đạt được các cơ sở dữ liệu hiệu quả và có cấu trúc tốt. Chúng ta cũng sẽ đề cập đến 6NF được đề xuất và đưa ra các ví dụ về chuẩn hóa cơ sở dữ liệu.
Giải thích khái niệm Chuẩn hóa
Chuẩn hóa là quá trình tổ chức dữ liệu trong cơ sở dữ liệu quan hệ để giảm thiểu sự dư thừa và phụ thuộc. Mục tiêu chính của chuẩn hóa là loại bỏ các bất thường dữ liệu, chẳng hạn như bất thường chèn, cập nhật và xóa, có thể dẫn đến sự không nhất quán và thiếu hiệu quả trong cơ sở dữ liệu.
Chuẩn hóa đạt được điều này bằng cách phân chia các bảng lớn thành các bảng nhỏ hơn, có liên quan và thiết lập mối quan hệ giữa chúng.
Các dạng chuẩn khác nhau (từ 1NF đến 5NF) và tầm quan trọng của chúng
Quy tắc 1NF (Dạng chuẩn thứ nhất)
- Giá trị nguyên tử: Mỗi cột trong bảng nên chứa các giá trị nguyên tử (không thể phân chia).
- Tên cột duy nhất: Mỗi cột nên có một tên duy nhất.
- Các hàng được sắp xếp: Thứ tự của các hàng trong bảng nên không quan trọng.
Quy tắc 2NF (Dạng chuẩn thứ hai)
- Phải thỏa mãn 1NF.
- Không có sự phụ thuộc một phần: Các thuộc tính không phải là khóa (các thuộc tính không phải là một phần của khóa chính) nên phụ thuộc vào toàn bộ khóa chính.
Quy tắc 3NF (Dạng chuẩn thứ ba)
- Phải thỏa mãn 2NF.
- Không có sự phụ thuộc bắc cầu: Các thuộc tính không phải là khóa không nên phụ thuộc vào các thuộc tính không phải là khóa khác.
Quy tắc 4NF (Dạng chuẩn thứ tư)
- Phải thỏa mãn 3NF.
- Không có sự phụ thuộc đa giá trị: Không nên có sự phụ thuộc đa giá trị giữa các thuộc tính.
Quy tắc 5NF (Dạng chuẩn thứ năm)
- Phải thỏa mãn 4NF.
- Không có sự phụ thuộc nối: Dữ liệu không nên được lưu trữ theo cách yêu cầu nối nhiều bảng để truy xuất thông tin.
6NF (Dạng chuẩn thứ sáu) được đề xuất
6NF là một dạng chuẩn được đề xuất nhưng ít được sử dụng, xử lý việc biểu diễn dữ liệu trong các cơ sở dữ liệu có khía cạnh thời gian và lịch sử.
Chuẩn hóa cơ sở dữ liệu với các ví dụ
Hãy xem xét một ví dụ để minh họa quá trình chuẩn hóa. Quay lại ví dụ trước đó về bảng sách.
Bảng này thể hiện sự dư thừa vì thông tin tác giả được lặp lại cho mỗi cuốn sách. Để chuẩn hóa bảng này, chúng ta sẽ tạo một bảng riêng cho Tác giả, loại bỏ sự dư thừa và đảm bảo tính toàn vẹn dữ liệu thông qua các mối quan hệ.
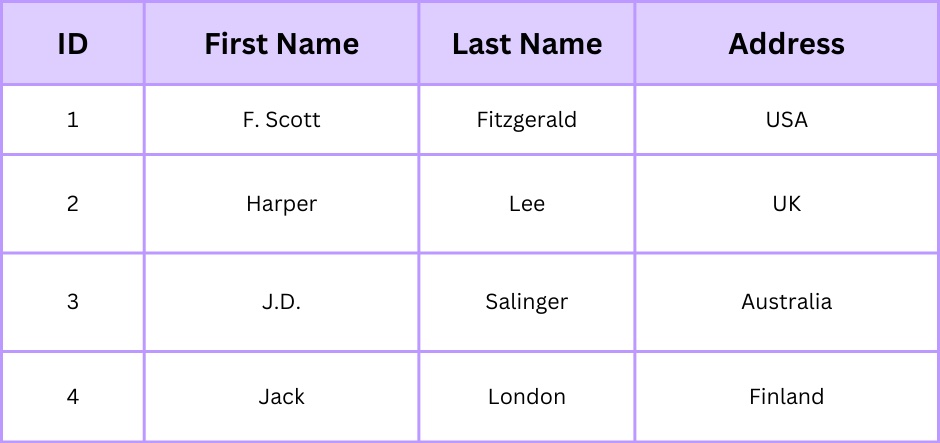
5. Ngôn ngữ truy vấn có cấu trúc (SQL)
Ngôn ngữ truy vấn có cấu trúc (SQL) là ngôn ngữ chuẩn để tương tác với cơ sở dữ liệu quan hệ. Nó cung cấp một phương tiện mạnh mẽ và linh hoạt để giao tiếp với cơ sở dữ liệu, cho phép người dùng thực hiện các thao tác như truy vấn, chèn, cập nhật và xóa dữ liệu. Trong phần này, chúng ta sẽ giới thiệu SQL, đề cập đến các thuật ngữ quan trọng và cung cấp tổng quan về các lệnh SQL cơ bản.
Giới thiệu SQL là ngôn ngữ dành cho Cơ sở dữ liệu quan hệ
SQL, viết tắt của Structured Query Language, là một ngôn ngữ chuyên dụng được thiết kế để quản lý và thao tác các hệ thống cơ sở dữ liệu quan hệ. Nó đóng vai trò như cầu nối giữa người dùng và cơ sở dữ liệu, cho phép người dùng tương tác với dữ liệu được lưu trữ bên trong.
SQL rất cần thiết cho nhiều tác vụ liên quan đến cơ sở dữ liệu, bao gồm:
- Truy xuất dữ liệu: Truy vấn cơ sở dữ liệu để truy xuất thông tin cụ thể.
- Thay đổi dữ liệu: Chèn, cập nhật hoặc xóa bản ghi trong cơ sở dữ liệu.
- Quản lý sơ đồ: Tạo, sửa đổi hoặc xóa bảng, chỉ mục và các cấu trúc cơ sở dữ liệu khác.
- Kiểm soát truy cập: Xác định và quản lý quyền và quyền truy cập của người dùng.
Các thuật ngữ quan trọng
Trước khi đi sâu vào các lệnh SQL, hãy làm quen với một số thuật ngữ SQL quan trọng:
- Cơ sở dữ liệu: Một tập hợp dữ liệu có cấu trúc được tổ chức thành các bảng, chỉ mục và các đối tượng liên quan khác.
- Bảng: Một đối tượng cơ sở dữ liệu cơ bản lưu trữ dữ liệu trong các hàng và cột.
- Hàng: Một bản ghi hoặc mục nhập dữ liệu duy nhất trong bảng.
- Cột: Một thuộc tính hoặc trường trong bảng lưu trữ một loại dữ liệu cụ thể.
- Khóa chính: Một mã định danh duy nhất cho mỗi hàng trong bảng, đảm bảo tính toàn vẹn dữ liệu.
- Khóa ngoại: Một cột trong một bảng thiết lập liên kết với khóa chính trong bảng khác, tạo ra mối quan hệ giữa các bảng.
- Truy vấn: Một yêu cầu được thực hiện trong SQL để truy xuất dữ liệu cụ thể từ một hoặc nhiều bảng.
- Câu lệnh SQL: Một lệnh SQL đơn lẻ thực hiện một hành động cụ thể, chẳng hạn như SELECT, INSERT, UPDATE hoặc DELETE.
Tổng quan về các lệnh SQL cơ bản
Các lệnh SQL có thể được phân loại rộng rãi thành bốn loại chính dựa trên chức năng của chúng:
-
Các lệnh truy vấn dữ liệu (SELECT): Các lệnh này được sử dụng để truy xuất dữ liệu từ một hoặc nhiều bảng trong cơ sở dữ liệu. Lệnh SQL cơ bản nhất để truy xuất dữ liệu là câu lệnh SELECT. Ví dụ:
SELECT * FROM KháchHàng;
-
Các lệnh sửa đổi dữ liệu (INSERT, UPDATE, DELETE): Các lệnh này được sử dụng để chèn, cập nhật hoặc xóa dữ liệu trong cơ sở dữ liệu. Ví dụ:
INSERT INTO ĐơnĐặtHàng (MãĐơn, MãKháchHàng, NgàyĐặt) VALUES (1, 101, '2023-09-06');UPDATE SảnPhẩm SET Giá = 1500 WHERE MãSảnPhẩm = 101;DELETE FROM KháchHàng WHERE MãKháchHàng = 201;
-
Các lệnh định nghĩa dữ liệu (CREATE, ALTER, DROP): Các lệnh này được sử dụng để định nghĩa và quản lý cấu trúc của các đối tượng cơ sở dữ liệu, chẳng hạn như bảng và chỉ mục. Ví dụ:
CREATE TABLE NhânViên (MãNV INT, Tên VARCHAR(50), Họ VARCHAR(50));ALTER TABLE KháchHàng ADD Email VARCHAR(100);DROP TABLE SảnPhẩm;
-
Các lệnh điều khiển dữ liệu (GRANT, REVOKE): Các lệnh này được sử dụng để quản lý quyền truy cập và quyền của người dùng đối với các đối tượng cơ sở dữ liệu. Ví dụ:
GRANT SELECT ON KháchHàng TO NgườiDùngA;REVOKE INSERT ON ĐơnĐặtHàng FROM NgườiDùngB;
Tính linh hoạt và sức mạnh biểu đạt của SQL làm cho nó trở thành một công cụ quan trọng đối với bất kỳ ai làm việc với cơ sở dữ liệu quan hệ. Trong các phần tiếp theo của bài viết này, chúng ta sẽ đi sâu hơn vào các thao tác SQL nâng cao, bao gồm nối, truy vấn con và nhiều kỹ thuật thao tác dữ liệu khác nhau, cung cấp các ví dụ thực tế để minh họa cách sử dụng của chúng.
6. Các thao tác SQL nâng cao
Trong phần này, chúng ta sẽ đi sâu hơn vào các thao tác SQL nâng cao cho phép bạn thao tác và truy vấn cơ sở dữ liệu quan hệ với độ chính xác và độ phức tạp cao hơn. Các thao tác nâng cao này bao gồm nối, truy vấn con, hàm cửa sổ, tổng hợp, biểu thức bảng chung (CTE), CTE đệ quy, hàm tạm thời, xoay dữ liệu, Except so với Not In, tự nối, hàm xếp hạng, tính toán giá trị delta, tính toán tổng chạy và thao tác ngày-giờ. Chúng ta sẽ cung cấp các ví dụ thực tế để minh họa từng thao tác này.
Nối
Nối cho phép bạn kết hợp dữ liệu từ nhiều bảng dựa trên một cột chung. Có nhiều loại nối khác nhau, bao gồm INNER JOIN, LEFT JOIN, RIGHT JOIN và FULL OUTER JOIN. Dưới đây là ví dụ về INNER JOIN:
SELECT ĐơnĐặtHàng.MãĐơn, KháchHàng.TênKháchHàng FROM ĐơnĐặtHàng INNER JOIN KháchHàng ON ĐơnĐặtHàng.MãKháchHàng = KháchHàng.MãKháchHàng;
Truy vấn con
Truy vấn con là các truy vấn được lồng vào trong một truy vấn chính. Chúng được sử dụng để truy xuất dữ liệu sẽ được sử dụng trong các điều kiện của truy vấn chính. Ví dụ:
SELECT TênSảnPhẩm FROM SảnPhẩm WHERE MãNhàCungCấp IN (SELECT MãNhàCungCấp FROM NhàCungCấp WHERE QuốcGia = 'Hoa Kỳ');
Hàm cửa sổ
Hàm cửa sổ thực hiện các phép tính trên một tập hợp các hàng bảng liên quan đến hàng hiện tại. Chúng thường được sử dụng để xếp hạng, tổng hợp và tính toán trung bình di động. Dưới đây là ví dụ sử dụng hàm cửa sổ RANK():
SELECT TênSảnPhẩm, DanhMục, Giá, RANK() OVER (PARTITION BY DanhMục ORDER BY Giá) AS XếpHạng FROM SảnPhẩm;
Tổng hợp
Tổng hợp cho phép bạn thực hiện các phép tính trên các nhóm hàng, thường được sử dụng với GROUP BY. Ví dụ:
SELECT DanhMục, AVG(Giá) AS GiáTrungBình FROM SảnPhẩm GROUP BY DanhMục;
Biểu thức bảng chung (CTE)
Biểu thức bảng chung (CTE) cung cấp một cách để tạo các tập kết quả tạm thời cho các truy vấn phức tạp. Dưới đây là một ví dụ:
WITH KháchHàngQuanTrong AS ( SELECT MãKháchHàng, COUNT(MãĐơn) AS SốĐơn FROM ĐơnĐặtHàng GROUP BY MãKháchHàng HAVING COUNT(MãĐơn) > 5 ) SELECT KháchHàng.TênKháchHàng, KháchHàngQuanTrọng.SốĐơn FROM KháchHàng INNER JOIN KháchHàngQuanTrọng ON KháchHàng.MãKháchHàng = KháchHàngQuanTrọng.MãKháchHàng;
CTE đệ quy
CTE đệ quy được sử dụng để làm việc với dữ liệu phân cấp. Chúng cho phép bạn tham chiếu CTE bên trong chính nó. Một ví dụ có thể liên quan đến việc biểu diễn phân cấp tổ chức.
WITH expression_name (column_list) AS ( -- Anchor member initial_query UNION ALL -- Recursive member that references expression_name. recursive_query ) -- references expression name SELECT * FROM expression_name
Hàm tạm thời
Hàm tạm thời là các hàm do người dùng định nghĩa có thể được sử dụng trong các truy vấn SQL. Chúng cho phép bạn đóng gói logic phức tạp và sử dụng lại nó trong các truy vấn của bạn.
CREATE OR REPLACE FUNCTION get_discounted_price(product_id INT)
RETURNS NUMERIC(10, 2)
AS
$$
DECLARE
original_price NUMERIC(10, 2);
discount_rate NUMERIC(5, 2);
discounted_price NUMERIC(10, 2);
BEGIN
SELECT price, discount INTO original_price,




