
[TIPS] HTMLタグの修正方法 - Python
By JoeVu, at: 2024年6月9日10:46
予想読書時間: __READING_TIME__ 分
![[TIPS] How to correct HTML tags - Python](/media/filer_public_thumbnails/filer_public/f0/d6/f0d63c49-f021-4a0c-a0be-772ac19dbef0/html-tag.png__1500x900_q85_crop_subsampling-2_upscale.jpg)
![[TIPS] How to correct HTML tags - Python](/media/filer_public_thumbnails/filer_public/f0/d6/f0d63c49-f021-4a0c-a0be-772ac19dbef0/html-tag.png__400x240_q85_crop_subsampling-2_upscale.jpg)
PythonのPythonを使って、壊れたHTMLタグを修正するには、bs4モジュールのBeautifulSoupのようなライブラリを使用できます。BeautifulSoupは、HTMLの解析と修正に強力です。
以下に、その使用方法に関するステップバイステップガイドを示します。
ステップ1:BeautifulSoupをインストールする
BeautifulSoupとlxml(パーサーライブラリ)をまだインストールしていない場合は、pipを使用してインストールできます。
pip install beautifulsoup4 lxml
ステップ2:BeautifulSoupを使用してHTMLを解析および修正する
以下は、HTML文字列を読み込み、BeautifulSoupで解析し、修正されたHTMLを出力するスクリプトの例です。
from bs4 import BeautifulSoup
# 壊れたHTMLコンテンツの例
messed_up_html = """ あなたのめちゃくちゃなHTMLコンテンツ """
# HTMLを解析する
soup = BeautifulSoup(messed_up_html, 'lxml')
# 修正されたHTMLを整形して出力する
corrected_html = soup.prettify()
print(corrected_html)
以下は、めちゃくちゃなHTMLタグのコンテンツです
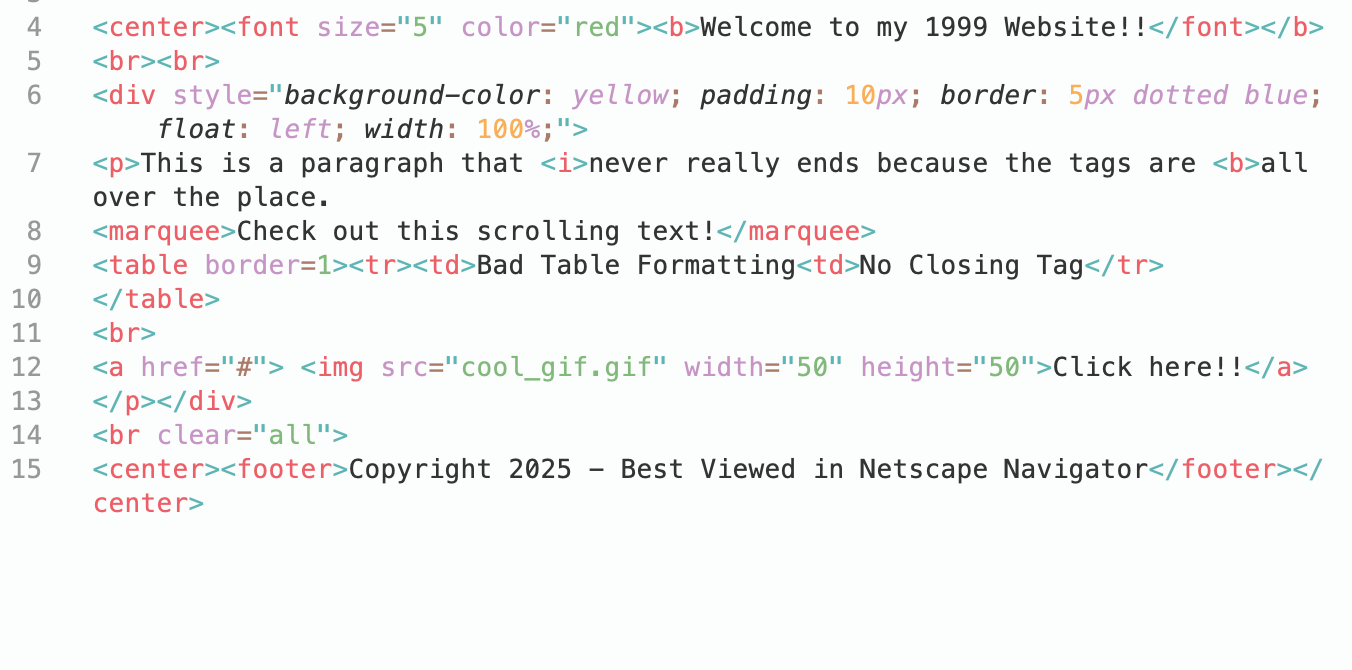
解説
- BeautifulSoup: HTMLおよびXMLドキュメントを解析するためのPythonライブラリ。ページソースコードから解析ツリーを作成し、HTMLからデータを抽出するために使用できます。
- lxml: BeautifulSoup用のパーサー。デフォルトのパーサーと比較して、壊れたHTMLに対してより高速で寛容です。
出力
prettifyメソッドはHTMLをきれいに整形します。修正されたHTMLは次のようになります。
from bs4 import BeautifulSoup
# 先ほどのめちゃくちゃなHTML文字列
messy_html = """
私の1999年のウェブサイトへようこそ! ここをクリックしてください!
ここをクリックしてください!"""
# 'html.parser'でライブラリを初期化します
# より堅牢なエラー修正には'lxml'を使用することもできます
soup = BeautifulSoup(messy_html, 'html.parser')
# .prettify()メソッドは、ネストを修正し、インデントを追加します
clean_html = soup.prettify()
print(clean_html)
代替手段
HTMLタグを検証し修正するためのオンラインサービスがいくつかあります。
![[TIPs] Common Mistakes with Python Dictionaries](/media/filer_public_thumbnails/filer_public/5f/97/5f97825e-ad69-4630-9b8e-d9ad6cd1c8c5/dictionary_common_issues.png__400x240_q85_crop_subsampling-2_upscale.jpg)
![[TIPS] How to Validate IP Address Using Python](/media/filer_public_thumbnails/filer_public/0f/65/0f659496-8f3d-4505-b7de-7e95a01edc0b/ip_address_validation.png__400x240_q85_crop_subsampling-2_upscale.jpg)
![[TIPS] Python - QR Code Exploration](/media/filer_public_thumbnails/filer_public/61/fd/61fd3ace-5879-4449-bf28-9f48c34aa359/python_-_qr_code.png__400x240_q85_crop_subsampling-2_upscale.jpg)

